Elastic App Search 快速构建 ES 应用
目录
公号:码农充电站pro
App Search 是 Elastic 家族中的一个产品,它可以帮助我们(基于 ES)快速高效的构建搜索应用。

App Search 的官方文档可参考这里。
1,安装 App Search
首先确保当前机器已安装 Java8 或 Java11 环境,并且需要有对应版本的 ElasticSearch。
1.1,下载 App Search 和 ES
在这里下载 App Search,根据自己的系统,选择相应的版本。
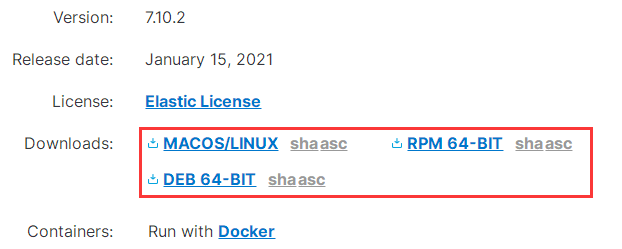
然后需要下载相应版本的 ES,我这里下载的都是 Linux 7.10.2 版的压缩包:
elasticsearch-7.10.2-linux-x86_64.tar.gz
enterprise-search-7.10.2.tar.gz
下载好之后将压缩包解压。
1.2,运行 ES
ES 要在安全模式运行,在 ES 的配置文件 config/elasticsearch.yml 中加入下面两行配置:
xpack.security.enabled: true
xpack.security.authc.api_key.enabled: true
使用下面命令运行 ES:
bin/elasticsearch
可以通过访问地址 http://localhost:9200/ 查看 ES 是否启动成功。
使用下面命令为 ES 的默认用户生成随机密码:
bin/elasticsearch-setup-passwords auto
密码如下(要记录下来,以后需要使用):
Changed password for user apm_system
PASSWORD apm_system = XkF0dLKfcs3Yww4p4r3l
Changed password for user kibana_system
PASSWORD kibana_system = NqAuVK8UA21Iit7nzEpn
Changed password for user kibana
PASSWORD kibana = NqAuVK8UA21Iit7nzEpn
Changed password for user logstash_system
PASSWORD logstash_system = nq6hwgzGXwrwnrZPTW5a
Changed password for user beats_system
PASSWORD beats_system = BhT671Xf0PWGrbqly5R3
Changed password for user remote_monitoring_user
PASSWORD remote_monitoring_user = SJ9j9KMZeT4WMQiOwLtG
Changed password for user elastic
PASSWORD elastic = 7RiVeroRF273yvqJdhlR
1.3,运行 App Search
在 App Search 的配置文件 config/enterprise-search.yml 中加入下面配置:
ent_search.auth.source: standard
elasticsearch.username: elastic
elasticsearch.password: 7RiVeroRF273yvqJdhlR
allow_es_settings_modification: true
注意 username 和 password 是在上面步骤生成的。
使用命令运行 App Search:
bin/enterprise-search
第一次会启动失败,并且输出如下内容:
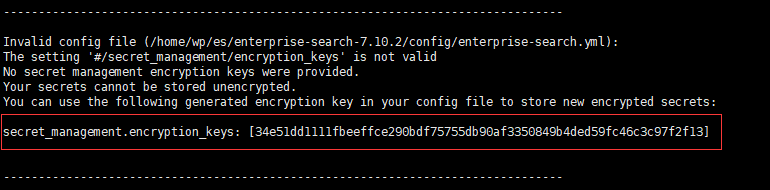
将 encryption_keys 写入配置文件 config/enterprise-search.yml:
secret_management.encryption_keys: [34e51dd1111fbeeffce290bdf75755db90af3350849b4ded59fc46c3c97f2f13]
再次启动 App Search,会输出一对用户名和密码(只会输出一次,注意记录):

该用户名密码用于登录 App Search:
username: enterprise_search
password: 6ucyhwfhsmx98miv
另外还会输出 secret_session_key:
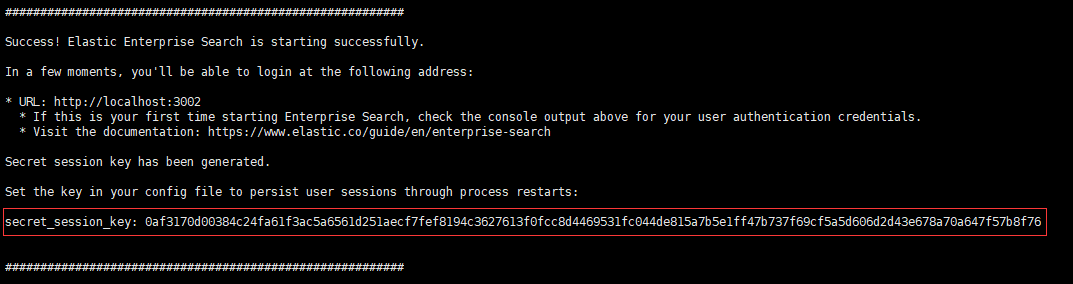
需要将 secret_session_key 写入配置文件,然后再次重启 App Search。
secret_session_key: 0af3170d00384c24fa61f3ac5a6561d251aecf7fef8194c3627613f0fcc8d4469531fc044de815a7b5e1ff47b737f69cf5a5d606d2d43e678a70a647f57b8f76
1.4,访问 App Search
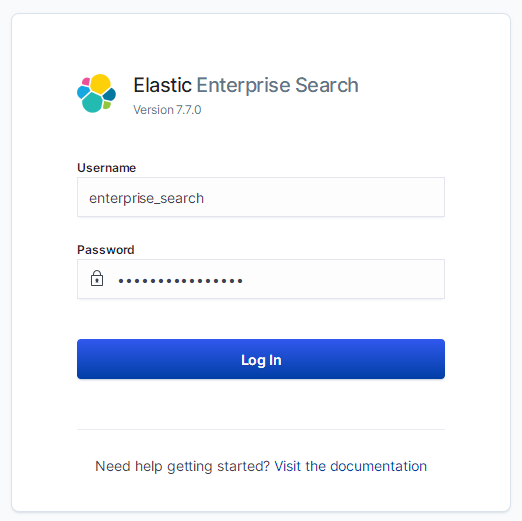
App Search 启动成功后,会在 3002 端口监听服务。
用浏览器访问地址 http://localhost:3002/,并使用上面步骤生成的用户名和密码登录系统:
到此为止,App Search 就可以使用了。
下面使用 App Search 构建一个电影搜索应用。
2,准备电影数据
我在这里准备了200 多条电影数据,每条电影数据包含多个字段,比如:
{
"publish_time": "1994-09-10",
"movie_time": "142",
"other_name": "月黑高飞(港) / 刺激1995(台) / 地狱诺言 / 铁窗岁月 / 消香克的救赎",
"year": "1994",
"classifications": "剧情/犯罪",
"score": "9.7",
"language": "英语",
"title": "肖申克的救赎 / The Shawshank Redemption / 月黑高飞(港) / 刺激1995(台)",
"introduction": "一场谋杀案使银行家安迪(蒂姆•罗宾斯 Tim Robbins 饰)蒙冤入狱,谋杀妻子及其情人的指控将囚禁他终生。在肖申克监狱的首次现身就让监狱“大哥”瑞德(摩根•弗里曼 Morgan Freeman 饰)对他另眼相看。瑞德帮助他搞到一把石锤和一幅女明星海报,两人渐成患难 之交。很快,安迪在监狱里大显其才,担当监狱图书管理员,并利用自己的金融知识帮助监狱官避税,引起了典狱长的注意,被招致麾下帮助典狱长洗黑钱。偶然一次,他得知一名新入狱的小偷能够作证帮他洗脱谋杀罪。燃起一丝希望的安迪找到了典狱长,希望他能帮自己翻案。阴险伪善的狱长假装答应安迪,背后却派人杀死小偷,让他唯一能合法出狱的希望泯灭。沮丧的安迪并没有绝望,在一个电闪雷鸣的风雨夜,一场暗藏几十年的越狱计划让他自我救赎,重获自由!老朋友瑞德在他的鼓舞和帮助下,也勇敢地奔向自由。本片获得1995年奥...",
"country": "美国",
"directors": "弗兰克·德拉邦特",
"writers": "弗兰克·德拉邦特 / 斯蒂芬·金",
"actors": "蒂姆·罗宾斯 / 摩根·弗里曼 / 鲍勃·冈顿 / 威廉姆·赛德勒 / 克兰西·布朗 / 吉尔·贝罗斯 / 马克·罗斯顿 / 詹姆斯·惠特摩 / 杰弗里·德曼 / 拉里·布兰登伯格 / 尼尔·吉恩托利 / 布赖恩·利比 / 大卫·普罗瓦尔 / 约瑟夫·劳格诺 / 祖德·塞克利拉 / 保罗·麦克兰尼 / 芮妮·布莱恩 / 阿方索·弗里曼 / V·J·福斯特 / 弗兰克·梅德拉诺 / 马克·迈尔斯 / 尼尔·萨默斯 / 耐德·巴拉米 / 布赖恩·戴拉特 / 唐·麦克马纳斯",
"img_url": "https://img2.doubanio.com/view/photo/s_ratio_poster/public/p480747492.webp"
}
每个字段的含义如下:
| 字段名称 | 含义 | 字段名称 | 含义 |
|---|---|---|---|
| publish_time | 发布时间 | title | 电影名称 |
| movie_time | 电影时长 | introduction | 电影简介 |
| other_name | 电影别名 | country | 发行国家 |
| year | 发布年份 | directors | 导演 |
| classifications | 电影分类 | writers | 编剧 |
| score | 电影评分 | actors | 主演 |
| language | 语言 | img_url | 封面地址 |
其中的字段 other_name、classifications、title、writers、actors 都是用斜杠分割。
3,创建 movies_db 项目
登录 App Search 后会进入如下页面:
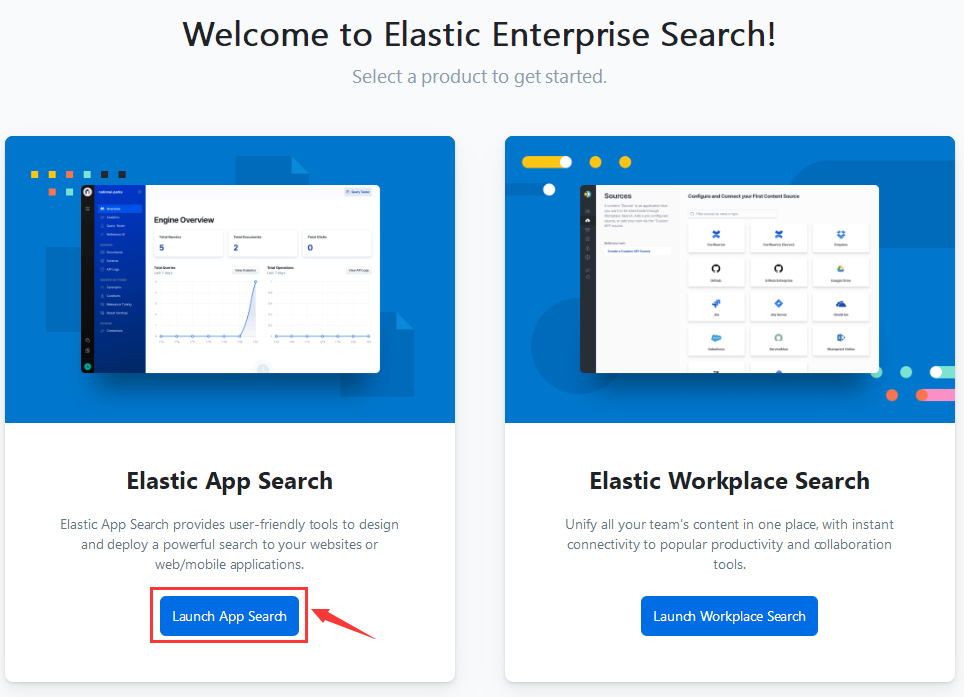
App Search 中的项目叫做 Engine,点击 Luanch App Search,创建一个搜索项目。
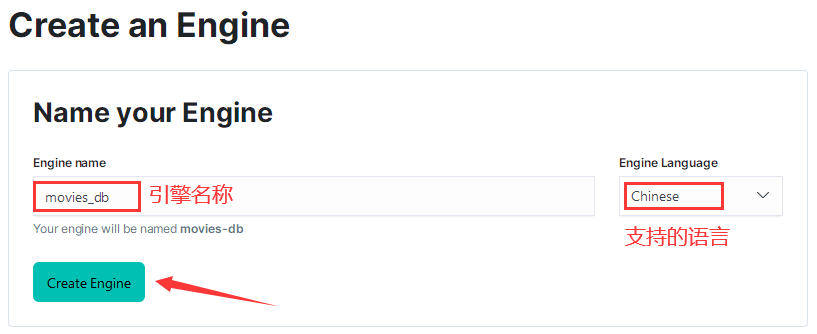
填写引擎名称和支持的语言,然后点击 Create Engine,创建引擎:
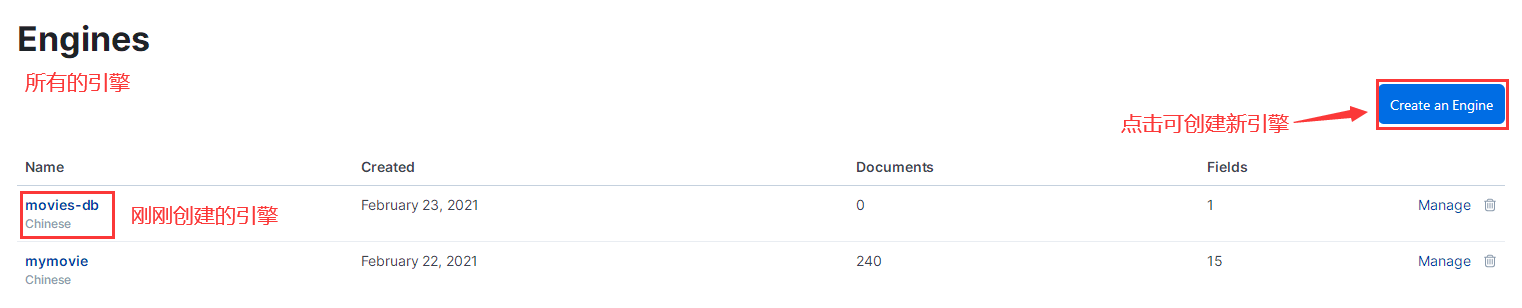
访问地址 http://localhost:3002/as#/engines/ 可以看到所有的项目:
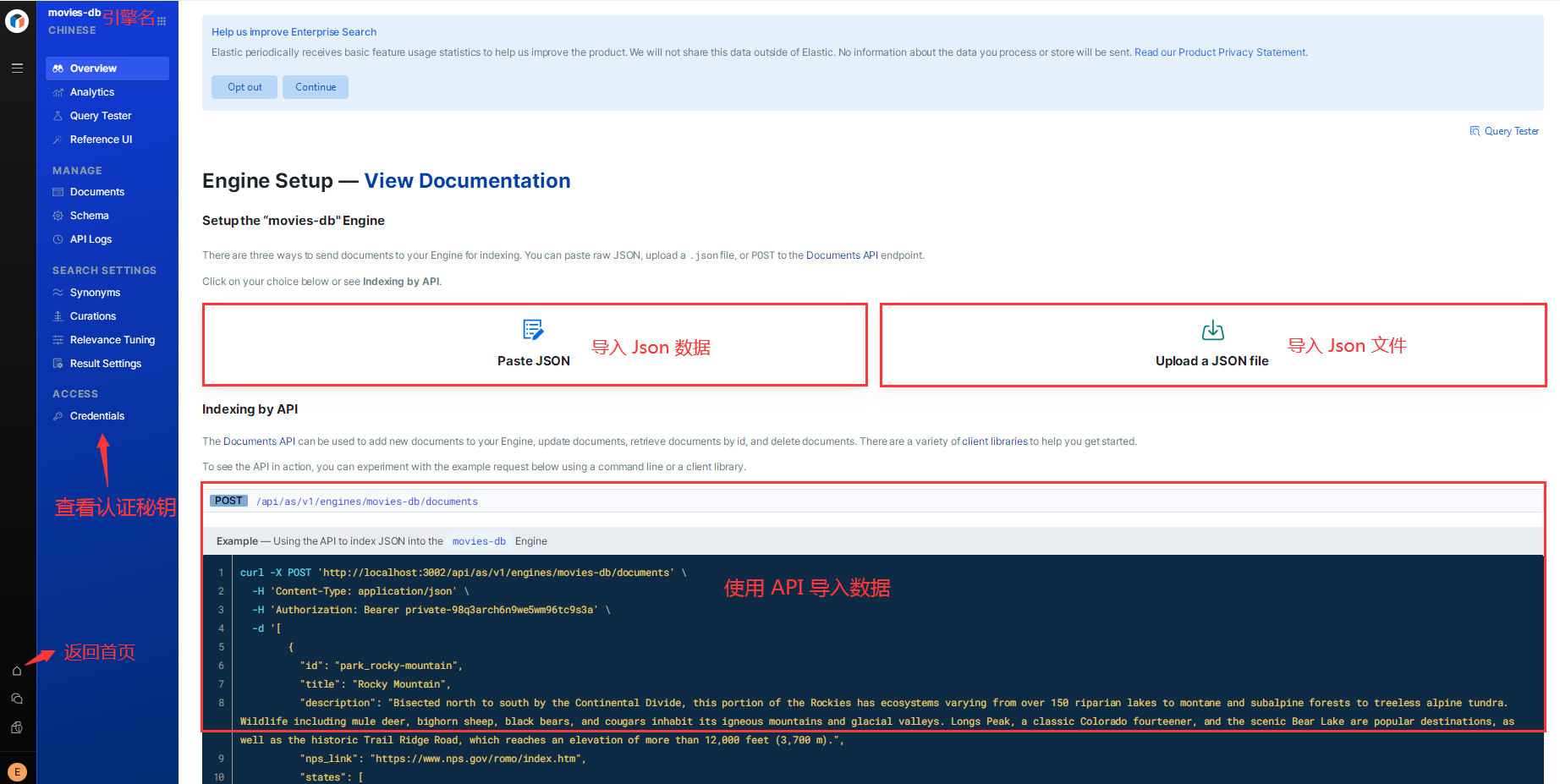
点击引擎名称,可进入引擎的管理界面:
4,导入电影数据
从上图中可看到,导入数据有三种方式:
- Paste JSON
- Upload a JSON file
- 使用 API 导入数据
使用 API 导入数据,需要用到秘钥,可通过点击 Credentials 查看秘钥:
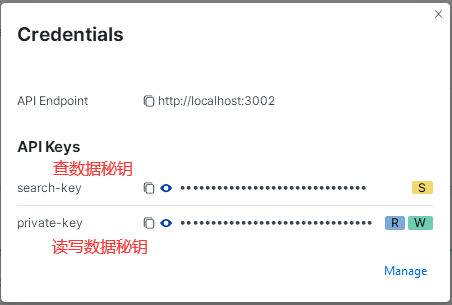
将 private-key 复制下来,用于写入电影数据。
Bearer private-98q3arch6n9we5wm96tc9s3a
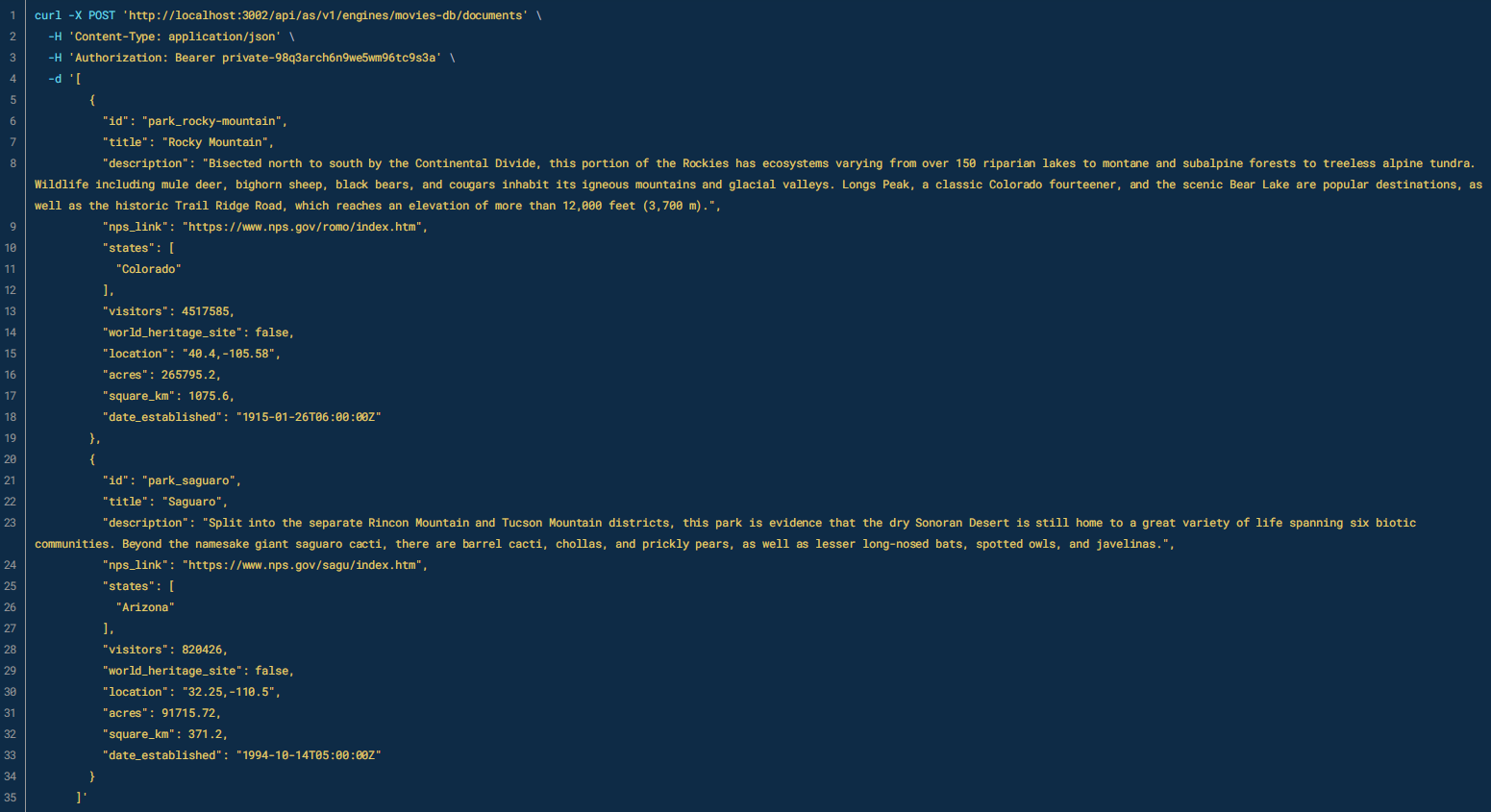
下面是使用 API 写入数据的请求格式:
4.1,使用 Python 写入数据
下面编写 Python 代码写入电影数据,代码如下:
#!/usr/bin/env python
# coding=utf-8
import sys
import json
import requests
reload(sys)
sys.setdefaultencoding('utf-8')
def read_file(file_name):
f = open(file_name)
lines = f.readlines()
for line in lines:
try:
line = json.loads(line)
except Exception, e:
continue
print 'movie_name:', line['title']
yield line
def transform_data(data):
other_name = data['other_name']
classifications = data['classifications']
title = data['title']
writers = data['writers']
actors = data['actors']
# 转成数组
other_name = [i.strip() for i in other_name.split('/')]
classifications = [i.strip() for i in classifications.split('/')]
title = [i.strip() for i in title.split('/')]
writers = [i.strip() for i in writers.split('/')]
actors = [i.strip() for i in actors.split('/')]
data['other_name'] = other_name
data['classifications'] = classifications
data['title'] = title
data['writers'] = writers
data['actors'] = actors
def import_doc(engine, authorization, doc):
url = 'http://localhost:3002/api/as/v1/engines/%s/documents' % engine
headers = {
"content-type" : "application/json",
"Authorization": authorization,
}
content=[doc]
try:
resp = requests.post(url, headers = headers, data = json.dumps(content))
print 'response:', resp
except Exception, e:
print e
if __name__== "__main__":
engine = 'movies-db'
authorization = 'Bearer private-98q3arch6n9we5wm96tc9s3a'
n = 0
for data in read_file('./movies.txt'):
transform_data(data)
import_doc(engine, authorization, data)
n += 1
print 'count:', n
5,管理数据
App Search 提供了一些功能,来帮助我们管理 ES 数据。
6,改变字段类型
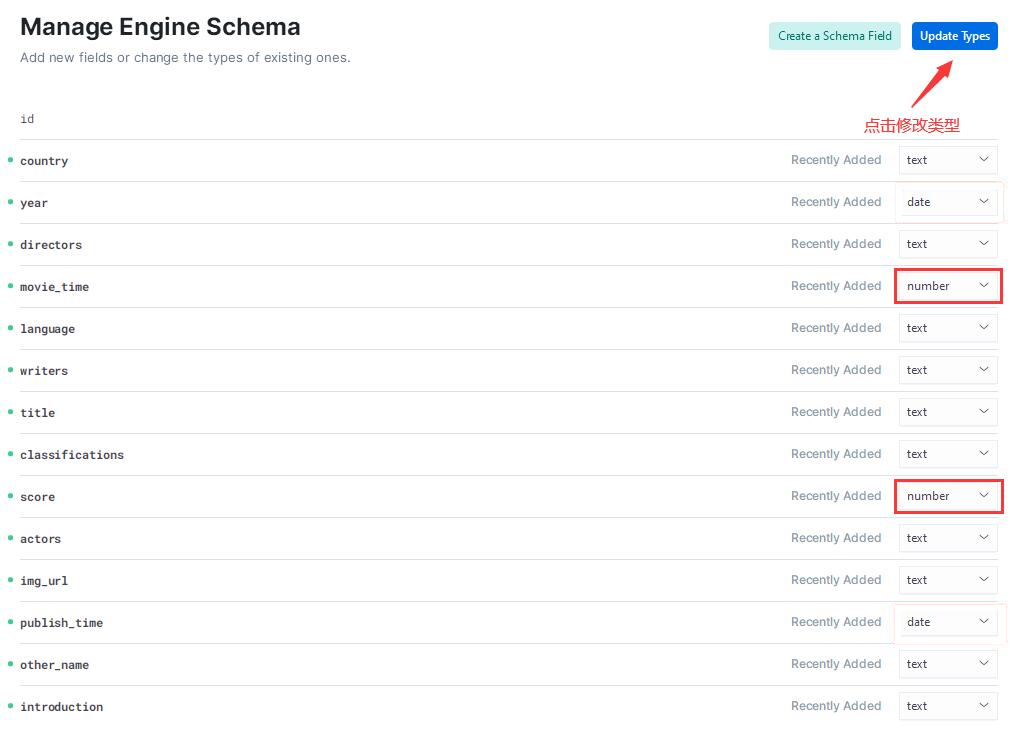
通过 Schema 可以修改字段的数据类型:

通过上图可以看到,ES 默认将数据的所有字段都处理成了 text 类型。
下面修改几个字段的数据类型:
修改字段的数据类型会重建索引。
7,生成 UI 界面
点击 Reference UI(基于search-ui ):
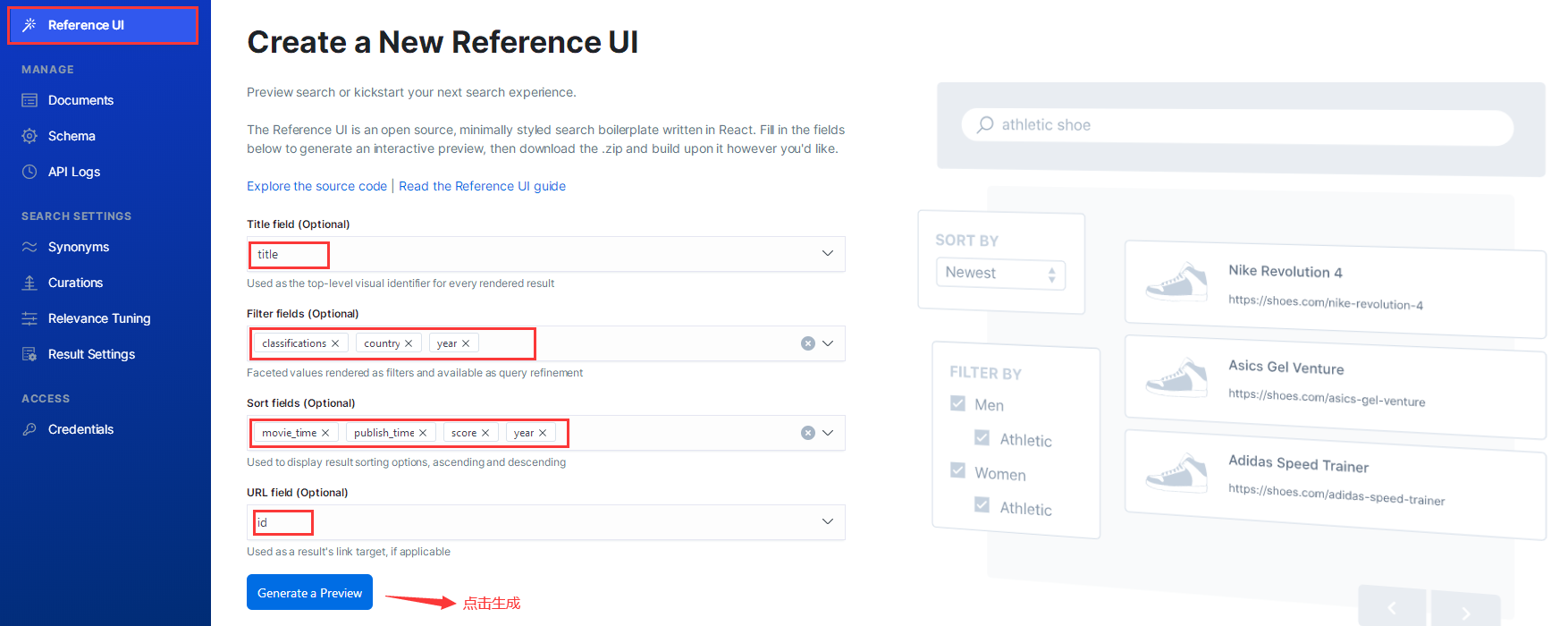
点击生成后,会跳转到如下页面:
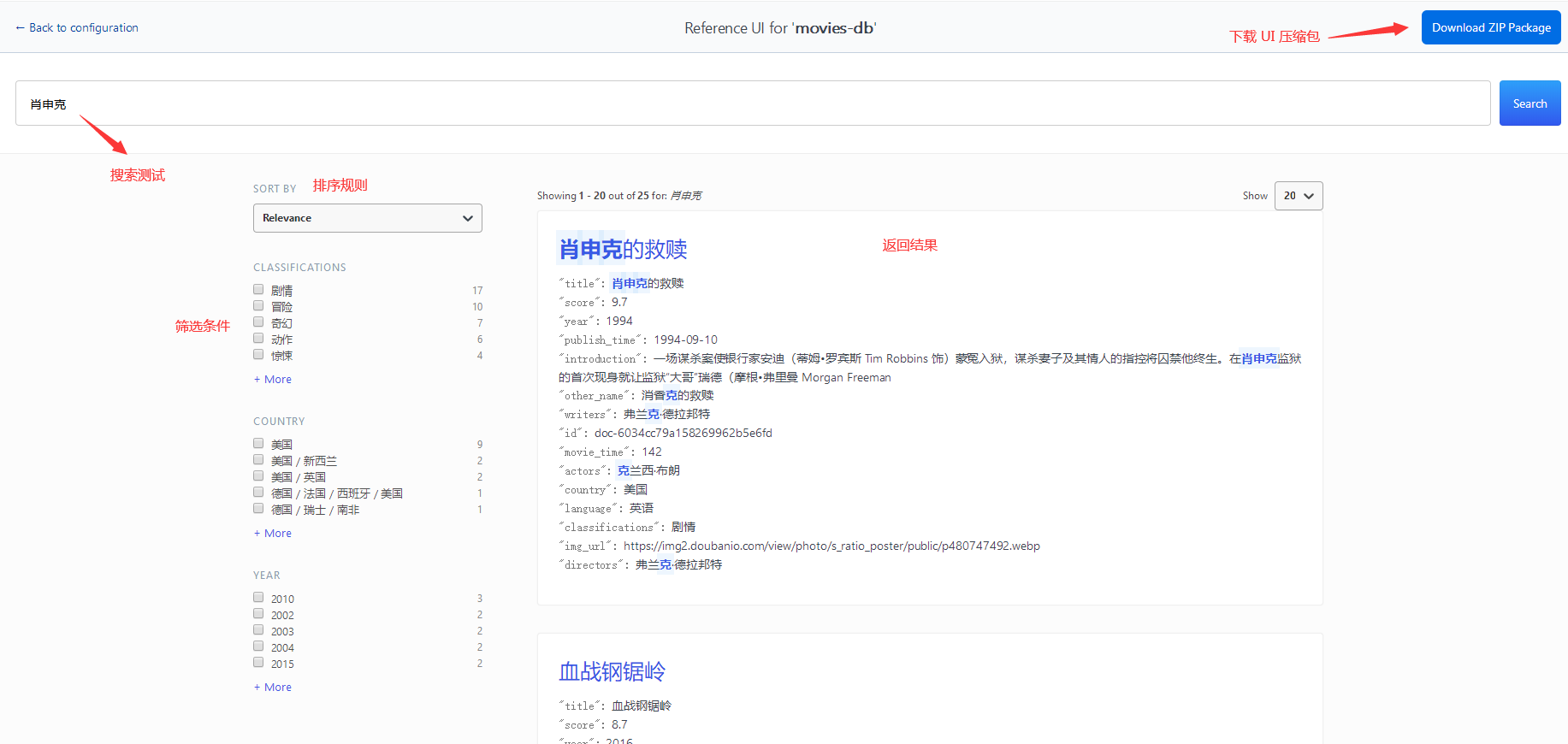
如果觉得没有问题,可下载 UI 压缩包。
movies-db-react-demo-ui.zip
7.1,使用压缩包
下载好压缩包后,将其解压。
使用 Reference UI 创建出来的界面是基于 nodejs 的,要保证其版本在 10 以上。
$ node -v
---------------
v12.16.3
使用如下命令安装 UI:
npm install
启动 UI:
npm start
启动成功后,通过 3000 端口http://localhost:3000 访问界面。
其它 UI 工具:
(本节完。)
推荐阅读:
欢迎关注作者公众号,获取更多技术干货。

文章作者 @码农加油站
上次更改 2021-02-28