ElasticSearch 中的 Mapping
目录
公号:码农充电站pro
1,ES 中的 Mapping
ES 中的 Mapping 相当于传统数据库中的表定义,它有以下作用:
- 定义索引中的字段的名字。
- 定义索引中的字段的类型,比如字符串,数字等。
- 定义索引中的字段是否建立倒排索引。
一个 Mapping 是针对一个索引中的 Type 定义的:
- ES 中的文档都存储在索引的 Type 中
- 在 ES 7.0 之前,一个索引可以有多个 Type,所以一个索引可拥有多个 Mapping
- 在 ES 7.0 之后,一个索引只能有一个 Type,所以一个索引只对应一个 Mapping
通过下面语法可以获取一个索引的 Mapping 信息:
GET index_name/_mapping
2,ES 字段的 mapping 参数
字段的 mapping 可以设置很多参数,如下:
- analyzer:指定分词器,只有 text 类型的数据支持。
- enabled:如果设置成
false,表示数据仅做存储,不支持搜索和聚合分析(数据保存在 _source 中)。- 默认值为
true。
- 默认值为
- index:字段是否建立倒排索引。
- 如果设置成
false,表示不建立倒排索引(节省空间),同时数据也无法被搜索,但依然支持聚合分析,数据也会出现在 _source 中。 - 默认值为
true。
- 如果设置成
- norms:字段是否支持算分。
- 如果字段只用来过滤和聚合分析,而不需要被搜索(计算算分),那么可以设置为
false,可节省空间。 - 默认值为
true。
- 如果字段只用来过滤和聚合分析,而不需要被搜索(计算算分),那么可以设置为
- doc_values:如果确定不需要对字段进行排序或聚合,也不需要从脚本访问字段值,则可以将其设置为
false,以节省磁盘空间。- 默认值为
true。
- 默认值为
- fielddata:如果要对 text 类型的数据进行排序和聚合分析,则将其设置为
true。- 默认为
false。
- 默认为
- store:默认值为
false,数据存储在 _source 中。- 默认情况下,字段值被编入索引以使其可搜索,但它们不会被存储。这意味着可以查询字段,但无法检索原始字段值。
- 在某些情况下,存储字段是有意义的。例如,有一个带有标题、日期和非常大的内容字段的文档,只想检索标题和日期,而不必从一个大的源字段中提取这些字段。
- boost:可增强字段的算分。
- coerce:是否开启数据类型的自动转换,比如字符串转数字。
- 默认是开启的。
- dynamic:控制 mapping 的自动更新,取值有
true,false,strict。 - eager_global_ordinals
- fields:多字段特性。
- 让一个字段拥有多个子字段类型,使得一个字段能够被多个不同的索引方式进行索引。
- copy_to
- format
- ignore_above
- ignore_malformed
- index_options
- index_phrases
- index_prefixes
- meta
- normalizer
- null_value:定义
null的值。 - position_increment_gap
- properties
- search_analyzer
- similarity
- term_vector
2.1,fields 参数
让一个字段拥有多个子字段类型,使得一个字段能够被多个不同的索引方式进行索引。
示例 1:
PUT index_name
{
"mappings": { # 设置 mappings
"properties": { # 属性,固定写法
"city": { # 字段名
"type": "text", # city 字段的类型为 text
"fields": { # 多字段域,固定写法
"raw": { # 子字段名称
"type": "keyword" # 子字段类型
}
}
}
}
}
}
示例 2 :
PUT index_name
{
"mappings": {
"properties": {
"title": { # 字段名称
"type": "text", # 字段类型
"analyzer": "english", # 字段分词器
"fields": { # 多字段域,固定写法
"std": { # 子字段名称
"type": "text", # 子字段类型
"analyzer": "standard" # 子字段分词器
}
}
}
}
}
}
3,ES 字段的数据类型
ES 中字段的数据类型有以下这些:
- 简单类型
- 复杂类型
- 特殊类型
text 类型与 keyword 类型
字符串数据可以定义成 text 或 keyword 类型,text 类型数据会做分词处理,而 keyword 类型数据不会做分词处理。
数组类型
对于数组类型 Arrays,ES 并没有提供专门的数组类型,但是任何字段都可以包含多个相同类型的数据,比如:
["one", "two"] # 一个字符串数组
[1, 2] # 一个整数数组
[1, [ 2, 3 ]] # 相当于 [ 1, 2, 3 ]
[{ "name": "Mary", "age": 12 }, { "name": "John", "age": 10 }] # 一个对象数组
当在 Mapping 中查看这些数组的类型时,其实还是数组中的元素的类型,而不是一个数组类型。
3.1,Nested 类型
Nested 是一种对象类型,它保留了子字段之间的关系。
1,为什么需要 Nested 类型
假如我们有如下结构的数据:
POST my_movies/_doc/1
{
"title":"Speed",
"actors":[ # actors 是一个数组类型,数组中的元素是对象类型
{
"first_name":"Keanu",
"last_name":"Reeves"
},
{
"first_name":"Dennis",
"last_name":"Hopper"
}
]
}
将数据插入 ES 之后,执行下面的查询:
# 查询电影信息
POST my_movies/_search
{
"query": {
"bool": {
"must": [
{"match": {"actors.first_name": "Keanu"}},
{"match": {"actors.last_name": "Hopper"}}
]
}
}
}
按照上面的查询语句,我们想查询的是 first_name=Keanu 且 last_name=Hopper 的数据,所以我们刚才插入的 id 为 1 的文档应该不符合这个查询条件。
但是在 ES 中执行上面的查询语句,却能查出 id 为 1 的文档。这是为什么呢?
这是因为,ES 对于这种 actors 字段这样的结构的数据,ES 并没有考虑对象的边界。
实际上,在 ES 内部,id 为 1 的那个文档是这样存储的:
"title":"Speed"
"actors.first_name":["Keanu","Dennis"]
"actors.last_name":["Reeves","Hopper"]
所以这种存储方式,并不是我们想象的那样。
如果我们查看 ES 默认为上面(id 为 1)结构的数据生成的 mappings,如下:
{
"my_movies" : {
"mappings" : {
"properties" : {
"actors" : { # actors 内部又嵌套了一个 properties
"properties" : {
"first_name" : { # 定义 first_name 的类型
"type" : "text",
"fields" : {
"keyword" : {"type" : "keyword", "ignore_above" : 256}
}
},
"last_name" : { # 定义 last_name 的类型
"type" : "text",
"fields" : {
"keyword" : {"type" : "keyword", "ignore_above" : 256}
}
}
}
}, # end actors
"title" : {
"type" : "text",
"fields" : {
"keyword" : {"type" : "keyword", "ignore_above" : 256}
}
}
}
}
}
}
那如何才能真正的表达一个对象类型呢?这就需要使用到 Nested 类型。
2,使用 Nested 类型
Nested 类型允许对象数组中的对象被独立(看作一个整体)索引。
我们对 my_movies 索引设置这样的 mappings:
DELETE my_movies
PUT my_movies
{
"mappings" : {
"properties" : {
"actors" : {
"type": "nested", # 将 actors 设置为 nested 类型
"properties" : { # 这时 actors 数组中的每个对象就是一个整体了
"first_name" : {"type" : "keyword"},
"last_name" : {"type" : "keyword"}
}},
"title" : {
"type" : "text",
"fields" : {"keyword":{"type":"keyword","ignore_above":256}}
}
}
}
}
写入数据后,在进行这样的搜索,就不会搜索出数据了:
# 查询电影信息
POST my_movies/_search
{
"query": {
"bool": {
"must": [
{"match": {"actors.first_name": "Keanu"}},
{"match": {"actors.last_name": "Hopper"}}
]
}
}
}
但是这样的查询也查不出数据:
POST my_movies/_search
{
"query": {
"bool": {
"must": [
{"match": {"actors.first_name": "Keanu"}},
{"match": {"actors.last_name": "Reeves"}}
]
}
}
}
3,搜索 Nested 类型
这是因为,查询 Nested 类型的数据,要像下面这样查询:
POST my_movies/_search
{
"query": {
"bool": {
"must": [
{
"nested": { # nested 查询
"path": "actors", # 自定 actors 字段路径
"query": { # 查询语句
"bool": {
"must": [
{"match": {"actors.first_name": "Keanu"}},
{"match": {"actors.last_name": "Hopper"}}
]
}
}
} # end nested
}
] # end must
} # end bool
}
}
4,聚合 Nested 类型
对 Nested 类型的数据进行聚合,示例:
# Nested Aggregation
POST my_movies/_search
{
"size": 0,
"aggs": {
"actors": { # 自定义聚合名称
"nested": { # 指定 nested 类型
"path": "actors" # 聚合的字段名称
},
"aggs": { # 子聚合
"actor_name": { # 自定义子聚合名称
"terms": { # terms 聚合
"field": "actors.first_name", # 子字段名称
"size": 10
}
}
}
}
}
}
使用普通的聚合方式则无法工作:
POST my_movies/_search
{
"size": 0,
"aggs": {
"actors": { # 自定义聚合名称
"terms": { # terms 聚合
"field": "actors.first_name",
"size": 10
}
}
}
}
3.2,Join 类型
Nested 类型的对象与其父/子级文档的关系,使得每次文档有更新的时候需要重建整个文档(包括根对象和嵌套对象)的索引。
Join 数据类型(类似关系型数据库中的 Join 操作)为同一索引中的文档定义父/子关系。
Join 数据类型可以维护一个父/子关系,从而分离两个对象,它的优点是:
- 父文档和子文档是两个完全独立的文档,这使得更新父文档不会影响到子文档,更新子文档也不会影响到父文档。
Nested 类型与 Join(Parent/Child) 类型的优缺点对比:

1,定义 Join 类型
定义 Join 类型的语法如下:
DELETE my_blogs
# 设定 Parent/Child Mapping
PUT my_blogs
{
"mappings": {
"properties": {
"blog_comments_relation": { # 字段名称
"type": "join", # 定义 join 类型
"relations": { # 定义父子关系
"blog": "comment" # blog 表示父级文档,comment 表示子级文档
}
},
"content": {
"type": "text"
},
"title": {
"type": "keyword"
}
}
}
}
2,插入 Join 数据
先插入两个父文档:
# 插入 blog1
PUT my_blogs/_doc/blog1
{
"title":"Learning Elasticsearch",
"content":"learning ELK @ geektime",
"blog_comments_relation":{
"name":"blog" # name 为 blog 表示父文档
}
}
# 插入 blog2
PUT my_blogs/_doc/blog2
{
"title":"Learning Hadoop",
"content":"learning Hadoop",
"blog_comments_relation":{
"name":"blog" # name 为 blog 表示父文档
}
}
插入子文档:
- 其中需要注意 routing 的值是父文档 id;
- 这样可以确保父子文档被索引到相同的分片,从而确保 join 查询的性能。
# 插入comment1
PUT my_blogs/_doc/comment1?routing=blog1 # routing 的值是父文档 id
{ # 确保父子文档被索引到相同的分片
"comment":"I am learning ELK",
"username":"Jack",
"blog_comments_relation":{
"name":"comment", # name 为 comment 表示子文档
"parent":"blog1" # 指定父文档的 id,表示子文档属于哪个父文档
}
}
# 插入 comment2
PUT my_blogs/_doc/comment2?routing=blog2 # routing 的值是父文档 id
{ # 确保父子文档被索引到相同的分片
"comment":"I like Hadoop!!!!!",
"username":"Jack",
"blog_comments_relation":{
"name":"comment", # name 为 comment 表示子文档
"parent":"blog2" # 指定父文档的 id,表示子文档属于哪个父文档
}
}
# 插入 comment3
PUT my_blogs/_doc/comment3?routing=blog2 # routing 的值是父文档 id
{ # 确保父子文档被索引到相同的分片
"comment":"Hello Hadoop",
"username":"Bob",
"blog_comments_relation":{
"name":"comment", # name 为 comment 表示子文档
"parent":"blog2" # 指定父文档的 id,表示子文档属于哪个父文档
}
}
3,parent_id 查询
根据父文档 id 来查询父文档,普通的查询无法查出子文档的信息:
GET my_blogs/_doc/blog2
如果想查到子文档的信息,需要使用 parent_id 查询:
POST my_blogs/_search
{
"query": {
"parent_id": { # parent_id 查询
"type": "comment", # comment 表示是子文档,即是表示想查询子文档信息
"id": "blog2" # 指定父文档的 id
} # 这样可以查询到 blog2 的所有 comment
}
}
4,has_child 查询
has_child 查询可以通过子文档的信息,查到父文档信息。
POST my_blogs/_search
{
"query": {
"has_child": { # has_child 查询
"type": "comment", # 指定子文档类型,表示下面的 query 中的信息要在 comment 子文档中匹配
"query" : {
"match": {"username" : "Jack"}
} # 在子文档中匹配信息,最终返回所有的相关父文档信息
}
}
}
5,has_parent 查询
has_parent 查询可以通过父文档的信息,查到子文档信息。
POST my_blogs/_search
{
"query": {
"has_parent": { # has_parent 查询
"parent_type": "blog", # 指定子文档类型,表示下面的 query 中的信息要在 blog 父文档中匹配
"query" : {
"match": {"title" : "Learning Hadoop"}
} # 在父文档中匹配信息,最终返回所有的相关子文档信息
}
}
}
6,通过子文档 id 查询子文档信息
普通的查询无法查到:
GET my_blogs/_doc/comment3
需要指定 routing 参数,提供父文档 id:
GET my_blogs/_doc/comment3?routing=blog2
7,更新子文档信息
更新子文档不会影响到父文档。
示例:
# URI 中指定子文档 id,并通过 routing 参数指定父文档 id
PUT my_blogs/_doc/comment3?routing=blog2
{
"comment": "Hello Hadoop??",
"blog_comments_relation": {
"name": "comment",
"parent": "blog2"
}
}
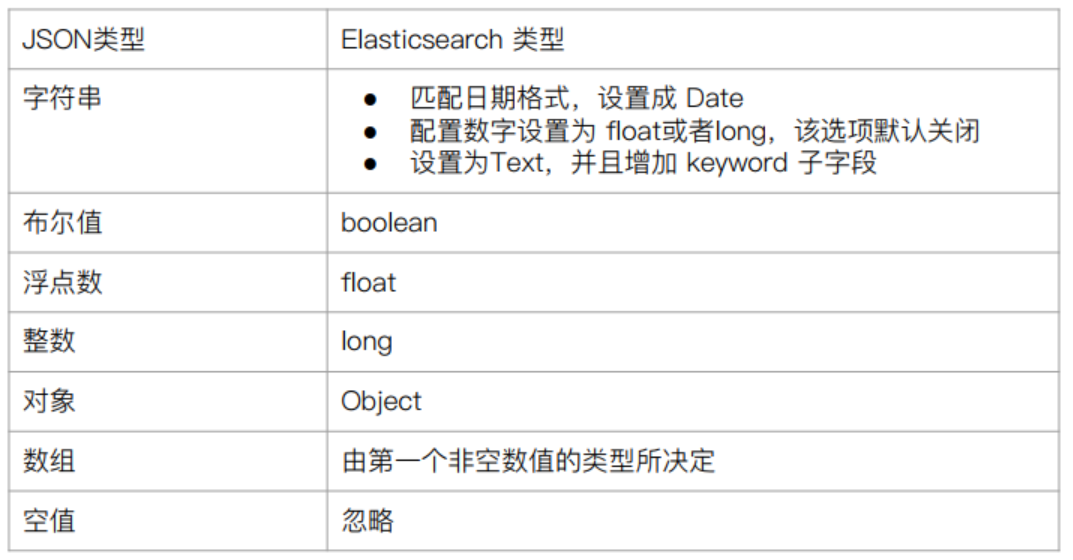
4,ES 动态 Mapping
ES 中的动态 Mapping 指的是:
- 在写入新文档的时候,如果索引不存在,ES 会自动创建索引。
- 动态 Mapping 使得我们可以不定义 Mapping,ES 会自动根据文档信息,推断出字段的类型。
- 但有时候也会推断错误,不符合我们的预期,比如地理位置信息等。
ES 类型的自动识别规则如下:
5,修改文档字段类型
字段类型是否能够修改,分两种情况:
- 对于新增字段:
- 如果
mappings._doc.dynamic为ture,当有新字段写入时,Mappings会自动更新。 - 如果
mappings._doc.dynamic为false,当有新字段写入时,Mappings不会更新;新增字段不会建立倒排索引,但是信息会出现在_source中。 - 如果
mappings._doc.dynamic为strict,当有新字段写入时,写入失败。
- 如果
- 对于已有字段:
- 字段的类型不允许再修改。因为如果修改了,会导致已有的信息无法被搜索。
- 如果希望修改字段类型,需要
Reindex重建索引。
dynamic 有 3 种取值,使用下面 API 可以修改 dynamic 的值:
PUT index_name/_mapping
{
"dynamic": false/true/strict
}
通过下面语法可以获取一个索引的 Mapping:
GET index_name/_mapping
6,自定义 Mapping
自定义 Mapping 的语法如下:
PUT index_name
{
"mappings" : {
# 定义
}
}
自定义 Mapping 的小技巧:
- 创建一个临时索引,写入一些测试数据
- 获取该索引的 Mapping 值,修改后,使用它创建新的索引
- 删除临时索引
Mappings 有很多参数可以设置,可以参考这里。
6.1,一个嵌套对象的 mappings
如果我们要在 ES 中插入如下结构的数据:
PUT blog/_doc/1
{
"content":"I like Elasticsearch",
"time":"2019-01-01T00:00:00",
"user": { # 是一个对象类型
"userid":1,
"username":"Jack",
"city":"Shanghai"
}
}
其中的 user 字段是一个对象类型。
这种结构的数据对应的 mappings 应该像下面这样定义:
PUT /blog
{
"mappings": {
"properties": {
"content": {
"type": "text"
},
"time": {
"type": "date"
},
"user": { # user 内部又嵌套了一个 properties
"properties": {
"city": {
"type": "text"
},
"userid": {
"type": "long"
},
"username": {
"type": "keyword"
}
}
}
}
}
}
6.2,一个对象数组的 mappings
如果我们要在 ES 中插入如下结构的数据:
POST my_movies/_doc/1
{
"title":"Speed",
"actors":[ # actors 是一个数组类型,数组中的元素是对象类型
{
"first_name":"Keanu",
"last_name":"Reeves"
},
{
"first_name":"Dennis",
"last_name":"Hopper"
}
]
}
其中的 actors 字段是一个数组类型,数组中的元素是对象类型。
像这种结构的数据对应的 mappings 应该像下面这样定义:
PUT my_movies
{
"mappings": {
"properties": {
"actors": { # actors 字段
"properties": { # 嵌入了一个 properties
"first_name": {"type": "keyword"},
"last_name": {"type": "keyword"}
}
},
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
7,控制字段是否可被索引
可以通过设置字段的 index 值,来控制某些字段是否可被搜索。
index 有两种取值:true / false,默认为 true。
当某个字段的 index 值为 false 时,ES 就不会为该字段建立倒排索引(节省空间),该字段也不能被搜索(如果搜索的话会报错)。
设置语法如下:
PUT index_name
{
"mappings" : { # 固定写法
"properties" : { # 固定写法
"firstName" : { # 字段名
"type" : "text"
},
"lastName" : { # 字段名
"type" : "text"
},
"mobile" : { # 字段名
"type" : "text",
"index": false # 设置为 false
}
}
}
}
8,控制倒排索引项的内容
我们可以通过设置 index_options 的值来控制倒排索引项的内容,它有 4 种取值:
docs:只记录文档 idfreqs:记录文档 id和词频positions:记录文档 id,词频和单词 positionoffsets:记录文档 id,词频,单词 position和字符 offset
Text 类型的数据,index_options 的值默认为 positions;其它类型的数据,index_options 的值默认为 docs。
注意:对于 index_options 的默认值,不同版本的 ES,可能不一样,请查看相应版本的文档。
对于倒排索引项,其记录的内容越多,占用的空间也就越大,同时 ES 也会对字段进行更多的分析。
设置语法如下:
PUT index_name
{
"mappings": { # 固定写法
"properties": { # 固定写法
"text": { # 字段名
"type": "text", # 字段的数据类型
"index_options": "offsets" # index_options 值
}
}
}
}
9,设置 null 值可被搜索
默认情况下 null 和 空数组[] 是不能够被搜索的,比如下面的两个文档:
PUT my_index/_doc/1
{
"status_code": null
}
PUT my_index/_doc/2
{
"status_code": []
}
要想使得这两个文档能够被搜索,需要设置 null_value 参数,如下:
PUT my_index
{
"mappings": {
"properties": {
"status_code": {
"type": "keyword", # 只有 Keyword 类型的数据,才支持设置 null_value
"null_value": "NULL" # 将 null_value 设置为 NULL,就可以通过 NULL 搜索了
}
}
}
}
注意只有 Keyword 类型的数据,才支持设置 null_value,将 null_value 设置为 NULL,就可以通过 NULL 搜索了,如下:
GET my-index/_search?q=status_code:NULL
10,索引模板
索引模板(Index Template)设置一个规则,自动生成索引的 Mappings 和 Settings。
索引模板有以下特性:
- 模板只在索引创建时起作用,修改模板不会影响已创建的索引。
- 可以设置多个索引模板,这些设置会被 merge 在一起。
- 可以设置 order 的数值,控制 merge 的过程。
多个模板时的 merge 规则,当一个索引被创建时:
- 使用 ES 默认的 mappings 和 settings。
- 使用 order 值低的模板。
- 使用 order 值高的模板,它会覆盖 order 值低的模板。
- 使用用户自带的,指定的 mappings 和 settings,这个级别的最高,会覆盖之前所有的。
对于相同字段的不同只会进行覆盖,对于不同的字段会进行叠加依次使用。
索引模板示例:
PUT _template/template_1 # template_1 是自定义的索引模板的名称
{
"index_patterns": ["te*", "bar*"], # 匹配索引的规则,该模板会作用于这些索引名上
"settings": { # settings 设置
"number_of_shards": 1
},
"mappings": { # mappings 设置
"_source": {
"enabled": false
},
"properties": {
"host_name": {
"type": "keyword"
},
"created_at": {
"type": "date",
"format": "EEE MMM dd HH:mm:ss Z yyyy"
}
}
}
}
多个索引模板:
PUT /_template/template_1
{
"index_patterns" : ["*"],
"order" : 0,
"settings" : {
"number_of_shards" : 1
},
"mappings" : {
"_source" : { "enabled" : false }
}
}
PUT /_template/template_2
{
"index_patterns" : ["te*"],
"order" : 1,
"settings" : {
"number_of_shards" : 1
},
"mappings" : {
"_source" : { "enabled" : true }
}
}
11,动态模板
动态模板(Dynamic Template)用于设置某个指定索引中的字段的数据类型。
(本节完。)
推荐阅读:
欢迎关注作者公众号,获取更多技术干货。

文章作者 @码农加油站
上次更改 2021-02-24