SVM 支持向量机算法-原理篇
目录
公号:码农充电站pro
本篇来介绍SVM 算法,它的英文全称是 Support Vector Machine,中文翻译为支持向量机。
之所以叫作支持向量机,是因为该算法最终训练出来的模型,由一些支持向量决定。所谓的支持向量,也就是能够决定最终模型的向量。
SVM 算法最初是用来解决二分类问题的,而在这个基础上进行扩展,也能够处理多分类问题以及回归问题。
1,SVM 算法的历史
早在1963 年,著名的前苏联统计学家弗拉基米尔·瓦普尼克在读博士期间,就和他的同事阿列克谢·切尔沃宁基斯共同提出了支持向量机的概念。
但由于当时的国际环境影响,他们用俄文发表的论文,并没有受到国际学术界的关注。
直到 20 世纪 90 年代,瓦普尼克随着移民潮来到美国,而后又发表了 SVM 理论。此后,SVM 算法才受到应有的重视。如今,SVM 算法被称为最好的监督学习算法之一。
2,线性可分的 SVM
SVM 算法最初用于解决二分类问题,下面我们以最简单的二维平面上的,线性可分的数据点来介绍支持向量机。
假设平面上有一些不同颜色的圆圈,这些圆圈是线性可分的,也就是可用一条直线分开。如下:
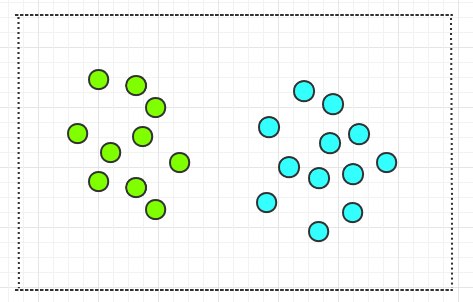
现在想在平面上画出一条直线,将这些圆圈分开。通过观察,你很容易就能画出一条直线,如下:
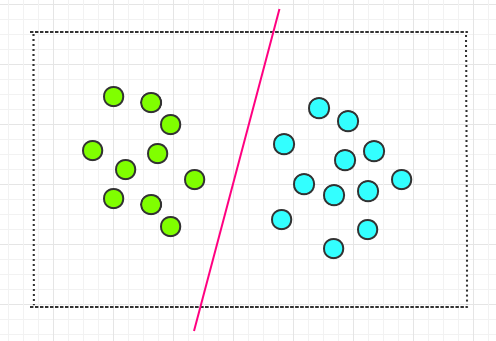
但是这样的直线会有很多,它们都能正确的划分两类圆圈,就像下面这幅图中的一样:
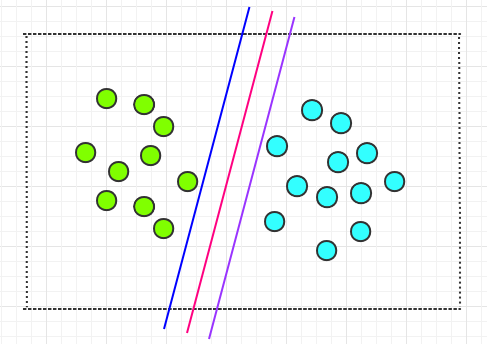
那么哪条直线才是最好的呢?通过肉眼我们无法找到那条最好的直线。但是就上图中的三条直线而言,明显你会觉得中间那条红线,会比两侧的两条线要更好。
因为,如果有一些圆圈往中间靠拢,那么两侧的那两条直线就不能将两种圆圈划分开了。而中间那条直线依然可以划分两种圆圈。如下:
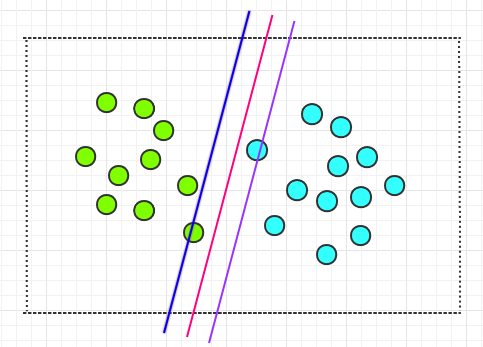
因此,中间那条红线会比两侧的两条直线更好,更安全。
虽然通过肉眼我们能知道哪条直线更好,但是怎样才能找到最好的那条直线呢?而 SVM 算法就可以帮我们找到那条最好的直线。
3,找到最好的直线
下面我们来看下如何找到最好的那条直线。
首先,找两条平行线,其中一条线经过一个绿色圆圈,剩下的所有绿色圆圈都在这条线的左侧;另一条线经过一个淡蓝色的圆圈,剩下的所有淡蓝色圆圈都在这条线的右侧。
如下图所示的两条平行线 L1 和 L2,L1 经过了 A 圆圈,L2 经过了 B 圆圈:
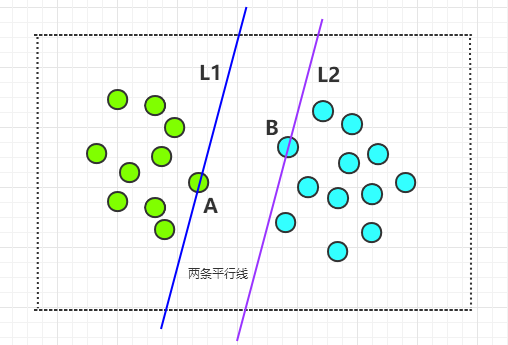
接下来,让 L1 以 A 为中心进行旋转,L2 以 B 为中心进行旋转,在旋转的过程中,要保证下面两个原则:
- L1 与 L2 保持平行。
- 除 A 之外的所有绿色圆圈都在 L1 的左侧,除 B之外的所有淡蓝色圆圈都在 L2 的右侧。
在保证上面两个原则的前提下旋转,直到其中的一条线经过第三个圆圈为止。如下:
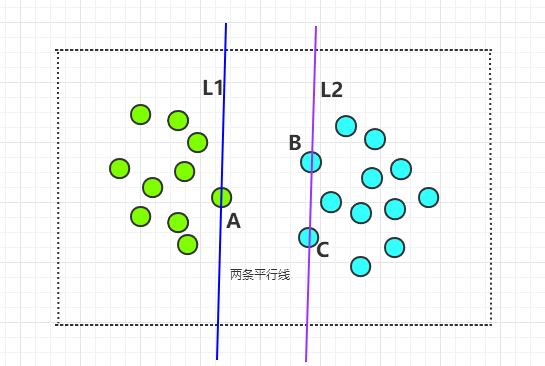
此时,L2 经过了第三个圆圈 C。
到此为止,我们要找的那条最好的,能够划分两种圆圈的直线,就是 L1 和 L2 中间的那条直线,如下图中的 L3:
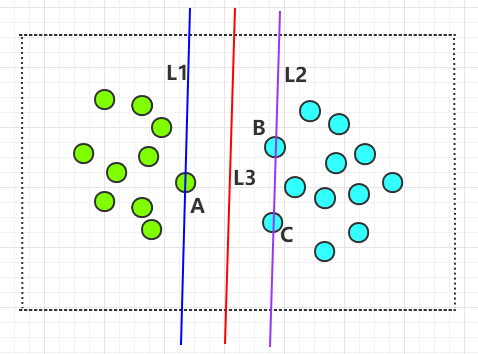
4,SVM 算法
SVM 算法的求解过程,就是寻找那条最佳直线的过程。
在 SVM 算法中,上面的 A,B,C 三个点叫作支持向量,直线 L3 是最佳直线,扩展到多维空间,这条直线叫作超平面。SVM 算法的目的就是找到这个超平面,这个超平面是划分数据点的最佳平面。
关于支持向量,更重要的是,SVM 训练出的最终模型,只与支持向量有关,这也是支持向量机的名称来源。就像 SVM 的发明者瓦普尼克所说的那样:支持向量机这个名字强调了这类算法的关键是如何根据支持向量构建出解,算法的复杂度也主要取决于支持向量的数目。
直线 L1 和 L2 之间有无数条平行直线都可以将两类圆圈分开,支持向量到这些平行直线的距离叫作分类间隔,而间隔最大的那条直线就是最佳直线,也就是 L3。
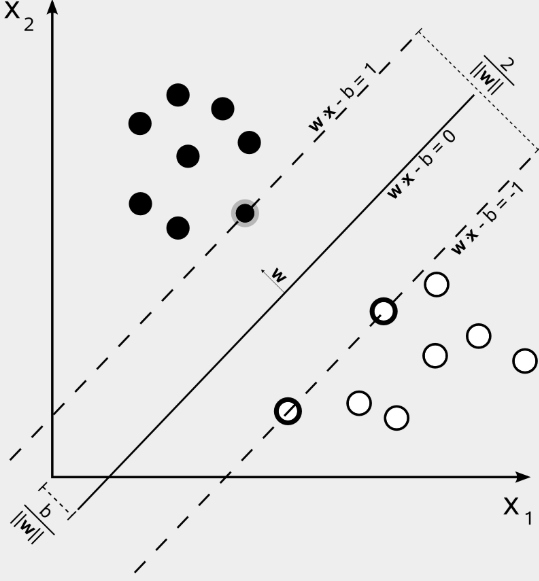
多维空间中的超平面可以用线性方程来表示:
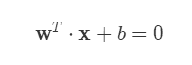
其中的 W 为法向量,它决定了超平面的方向。b 为截距,它决定了超平面与空间原点的距离。
超平面将特征空间分为两部分,法向量所指向的一侧的数据为正类,标记为 +1;另一侧的数据为负类,标记为 -1。
二维坐标系中的线性方程如下图所示:
支持向量机的学习过程是一个凸二次规划问题,可以用 SMO 算法高效求解。
SMO 全称为 Sequential Minimal Optimization,中文称为序列最小优化,由 John Platt 于 1996 年发表。
5,线性 SVM
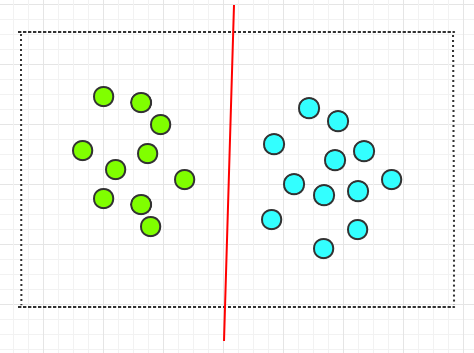
上文中介绍到的两类圆圈是线性可分的,也就是可以用一条直线将所有不同的圆圈划分开,而不允许有一个例外。如下:
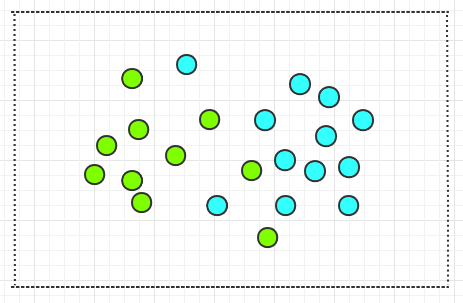
但现实生活中的数据,往往是线性不可分的,如下图中的两类圆圈,就不可能找到一条直线将其分开:
使用线性可分的 SVM 是无法解决线性不可分问题的。要想解决线性不可分问题,就得将支持向量机一般化,这种向量机称为线性 SVM(去掉了可分二字)。
线性 SVM 比线性可分SVM 更具通用性。线性可分SVM 寻求的是硬间隔最大化,而线性 SVM寻求的是软间隔最大化。
硬件隔不允许有一个例外的点被错分,而软间隔则允许个别(不会很多)的点被错分。
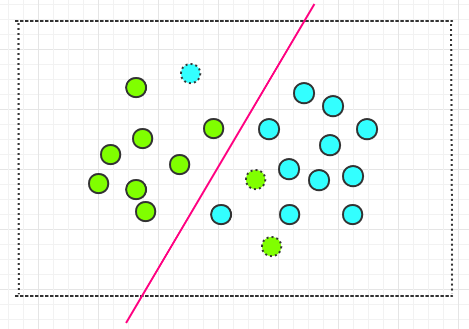
在线性不可分的数据集中,导致不可分的只是少量异常点,只要把这些异常点去掉,余下的大部分样本点依然满足线性可分的条件。如下图所示:
6,非线性问题
不管是线性可分 SVM 还是线性 SVM,它们都只能处理线性问题:
- 线性可分 SVM:存在一条直线将所有的点正确划分。
- 线性 SVM:存在一条直线将绝大部分点正确划分,而允许极个别点错分。这些极个别点可称为噪点或异常点。
与线性问题相对应的是非线性问题,比如下面两种情况都是非线性问题:
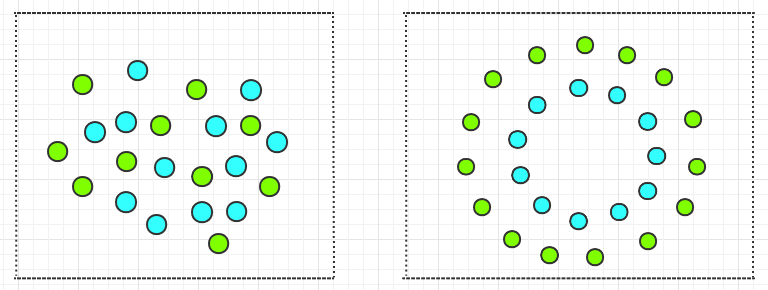
如何让 SVM 处理非线性问题呢?
7,核函数
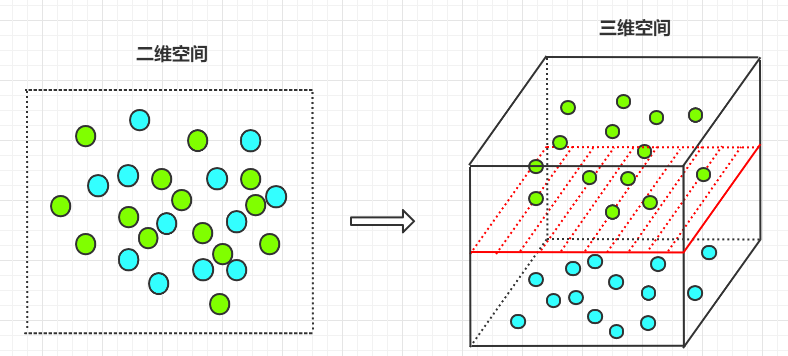
既然在二维空间中,不能找到一条直线来处理非线性问题。那么是否可以将二维空间映射成三维空间,从而找到一个平面,来处理二维空间不能处理的问题呢?
答案是肯定的,如果样本的属性数有限,那么就一定存在一个高维特征空间使样本线性可分。
如下图所示,在二维空间时,不能找到一条直线将其正确的分类;将其映射到三维空间后,可以找到一个平面,将其正确分类:
从下面这幅动图可直观的看到,二维空间的线性不可分映射到三维空间线性可分的转换过程:
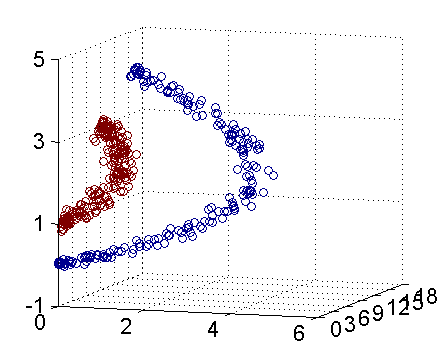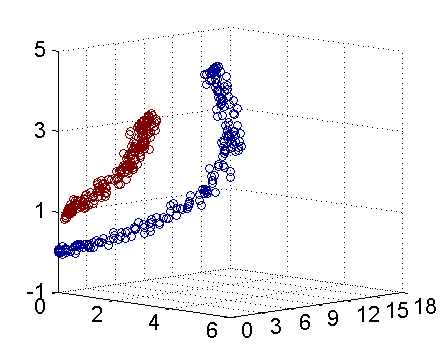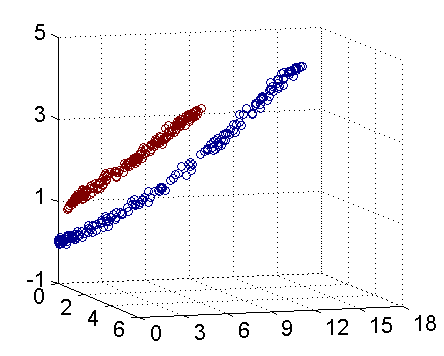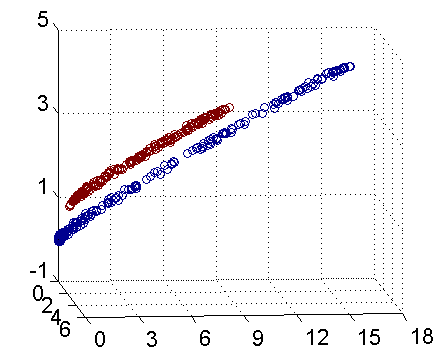
将原始低维空间上的非线性问题转化为新的高维空间上的线性问题,这就是核技巧的基本思想。
支持向量机诞生于 1963 年,核技巧诞生于 1995 年。
在支持向量机中,核函数可以将样本从低维空间映射到高维空间,从而使得 SVM 可以处理非线性问题。常用的核函数有以下几种:
- 线性核函数
- 多项式核函数
- 高斯核函数
- 拉普拉斯核函数
- Sigmoid 核函数
不同的核函数对应不同的映射方式。在SVM 算法中,核函数的选择非常关键,好的核函数会将样本映射到合适的特征空间,从而训练出更优的模型。
核函数将线性SVM 扩展成了非线性 SVM,使得 SVM 更具普适性。
8,多分类问题
SVM 算法最初用于处理二分类问题,那它如何处理多分类问题呢?
对于多分类问题,可以将多个二分类器组合起来形成一个多分类器,常见的方法有一对多法和一对一法。
一对多法
对于有 K 个分类的数据集,把其中的一类作为正集,其它的 K-1 类作为负集,这样就把数据集分了正负两类。
比如我们有一个数据集,该数据集有三个分类 A,B,C,那么将训练出三个分类器:
- 将分类 A 作为正集,B,C 作为负集,训练出一个分类器。
- 将分类 B 作为正集,A,C 作为负集,训练出一个分类器。
- 将分类 C 作为正集,A,B 作为负集,训练出一个分类器。
如下图所示:
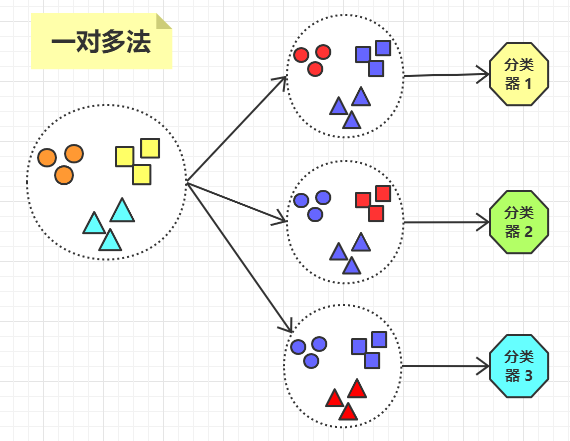
对于 K 个分类的数据集,一对多法会训练出 K 个分类器。缺点是,每次训练分类器时,负样本数都大大多于正样本数,造成样本分布不均。
一对一法
对于有 K 个分类的数据集,任选其中的两类样本,然后训练出一个分类器。
比如我们有一个数据集,该数据集有三个分类 A,B,C,那么将训练出三个分类器:
- 选 A,B 两类数据,训练出一个分类器。
- 选 A,C 两类数据,训练出一个分类器。
- 选 B,C 两类数据,训练出一个分类器。
如下图所示:
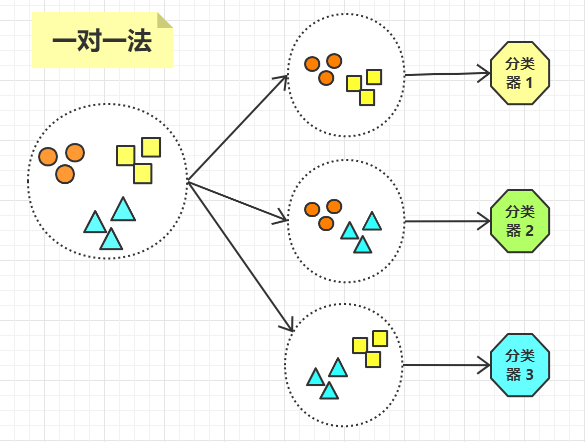
那么这种方法将会训练出 C(K, 2) 个分类器,因此这种方法的缺点是,如果数据集的分类较多的话,训练出的分类器将会非常多。
9,总结
SVM 算法通过寻找一个超平面来处理分类问题。这个超平面只与几个支持向量有关,而不会受其它的普通向量的影响。
SVM 可分为线性 SVM 和非线性 SVM,线性 SVM 只能处理线性问题,而不能处理非线性问题。
核函数可以将低维空间的非线性问题,转化为高维空间的线性问题,这就将线性 SVM 扩展成了非线性 SVM,从而使得 SVM 可以处理非线性问题。
SVM 算法最初用来处理二分类问题,对于多分类问题,可以将多个二分类器组合在一起成为一个多分类器,从而处理多分类问题。方法有一对多法和一对一法。
下一节将介绍如何用 SVM 处理实际问题。
(本节完。)
推荐阅读:
欢迎关注作者公众号,获取更多技术干货。

文章作者 @码农加油站
上次更改 2021-01-18