RandomForest 随机森林算法与模型参数的调优
目录
公号:码农充电站pro
本篇文章来介绍随机森林(RandomForest)算法。
1,集成算法之 bagging 算法
在前边的文章《AdaBoost 算法-分析波士顿房价数据集》中,我们介绍过集成算法。集成算法中有一类算法叫做 bagging 算法。
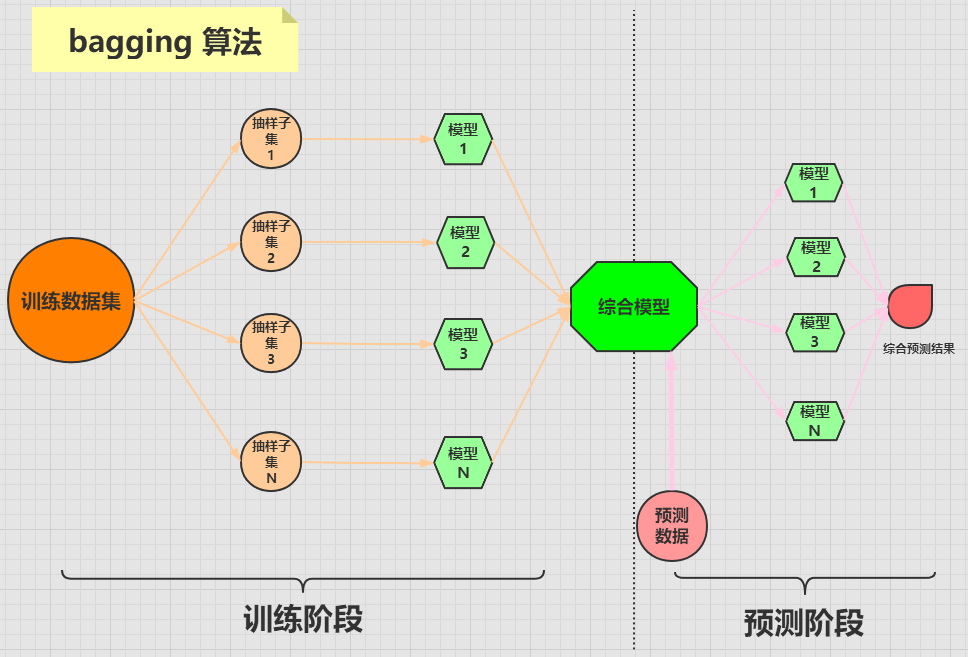
bagging 算法是将一个原始数据集随机抽样成 N 个新的数据集。然后将这 N 个新的数据集作用于同一个机器学习算法,从而得到 N 个模型,最终集成一个综合模型。
在对新的数据进行预测时,需要经过这 N 个模型(每个模型互不依赖干扰)的预测(投票),最终综合 N 个投票结果,来形成最后的预测结果。
bagging 算法的流程可用下图来表示:
2,随机森林算法
随机森林算法是 bagging 算法中比较出名的一种。
随机森林算法由多个决策树分类器组成,每一个子分类器都是一棵 CART 分类回归树,所以随机森林既可以做分类,又可以做回归。
当随机森林算法处理分类问题的时候,分类的最终结果是由所有的子分类器投票而成,投票最多的那个结果就是最终的分类结果。
当随机森林算法处理回归问题的时候,最终的结果是每棵 CART 树的回归结果的平均值。
3,随机森林算法的实现
sklearn 库即实现了随机森林分类树,又实现了随机森林回归树:
RandomForestClassifier 类的原型如下:
RandomForestClassifier(n_estimators=100,
criterion='gini', max_depth=None,
min_samples_split=2, min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
bootstrap=True, oob_score=False,
n_jobs=None, random_state=None,
verbose=0, warm_start=False,
class_weight=None, ccp_alpha=0.0,
max_samples=None)
可以看到分类树的参数特别多,我们来介绍几个重要的参数:
- n_estimators:随机森林中决策树的个数,默认为 100。
- criterion:随机森林中决策树的算法,可选的有两种:
- gini:基尼系数,也就是 CART 算法,为默认值。
- entropy:信息熵,也就是 ID3 算法。
- max_depth:决策树的最大深度。
RandomForestRegressor 类的原型如下:
RandomForestRegressor(n_estimators=100,
criterion='mse', max_depth=None,
min_samples_split=2, min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
bootstrap=True, oob_score=False,
n_jobs=None, random_state=None,
verbose=0, warm_start=False,
ccp_alpha=0.0, max_samples=None)
回归树中的参数与分类树中的参数基本相同,但 criterion 参数的取值不同。
在回归树中,criterion 参数有下面两种取值:
- mse:表示均方误差算法,为默认值。
- mae:表示平均误差算法。
4,随机森林算法的使用
下面使用随机森林分类树来处理鸢尾花数据集,该数据集在《决策树算法-实战篇》中介绍过,这里不再介绍,我们直接使用它。
首先加载数据集:
from sklearn.datasets import load_iris
iris = load_iris() # 准备数据集
features = iris.data # 获取特征集
labels = iris.target # 获取目标集
将数据分成训练集和测试集:
from sklearn.model_selection import train_test_split
train_features, test_features, train_labels, test_labels =
train_test_split(features, labels, test_size=0.33, random_state=0)
接下来构造随机森林分类树:
from sklearn.ensemble import RandomForestClassifier
# 这里均使用默认参数
rfc = RandomForestClassifier()
# 训练模型
rfc.fit(train_features, train_labels)
estimators_ 属性中存储了训练出来的所有的子分类器,来看下子分类器的个数:
>>> len(rfc.estimators_)
100
预测数据:
test_predict = rfc.predict(test_features)
测试准确率:
>>> from sklearn.metrics import accuracy_score
>>> accuracy_score(test_labels, test_predict)
0.96
5,模型参数调优
在机器学习算法模型中,一般都有很多参数,每个参数都有不同的取值。如何才能让模型达到最好的效果呢?这就需要参数调优。
sklearn 库中有一个 GridSearchCV 类,可以帮助我们进行参数调优。
我们只要告诉它想要调优的参数有哪些,以及参数的取值范围,它就会把所有的情况都跑一遍,然后告诉我们参数的最优取值。
先来看下 GridSearchCV 类的原型:
GridSearchCV(estimator,
param_grid, scoring=None,
n_jobs=None, refit=True,
cv=None, verbose=0,
pre_dispatch='2*n_jobs',
error_score=nan,
return_train_score=False)
其中有几个重要的参数:
- estimator:表示为哪种机器学习算法进行调优,比如随机森林,决策树,SVM 等。
- param_grid:要优化的参数及取值,输入的形式是字典或列表。
- scoring:准确度的评价标准。
- cv:交叉验证的折数,默认是三折交叉验证。
下面我们对随机森林分类树进行参数调优,还是使用鸢尾花数据集。
首先载入数据:
from sklearn.datasets import load_iris
iris = load_iris()
构造分类树:
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier()
如果我们要对分类树的 n_estimators 参数进行调优,调优的范围是 [1, 10],则准备变量:
param = {"n_estimators": range(1,11)}
创建 GridSearchCV 对象,并调优:
from sklearn.model_selection import GridSearchCV
gs = GridSearchCV(estimator=rfc, param_grid=param)
# 对iris数据集进行分类
gs.fit(iris.data, iris.target)
输出最优准确率和最优参数:
>>> gs.best_score_
0.9666666666666668
>>> gs.best_params_
{'n_estimators': 7}
可以看到,最优的结果是 n_estimators 取 7,也就是随机森林的子决策树的个数是 7 时,随机森林的准确度最高,为 0.9667。
6,总结
本篇文章主要介绍了随机森林算法的原理及应用,并展示了如何使用 GridSearchCV 进行参数调优。
(本节完。)
推荐阅读:
欢迎关注作者公众号,获取更多技术干货。

文章作者 @码农加油站
上次更改 2021-01-17