决策树算法-实战篇-鸢尾花及波士顿房价预测
目录
公号:码农充电站pro
上篇文章介绍了决策树算法的理论篇,本节来介绍如何用决策树解决实际问题。
决策树是常用的机器学习算法之一,决策树模型的决策过程非常类似人类做判断的过程,比较好理解。
决策树可用于很多场景,比如金融风险评估,房屋价格评估,医疗辅助诊断等。
要使用决策树算法,我们先来介绍一下 scikit-learn 。
1,scikit-learn
scikit-learn 是基于Python 的一个机器学习库,简称为sklearn,其中实现了很多机器学习算法。我们可以通过sklearn 官方手册 来学习如何使用它。
sklearn 自带数据集
要进行数据挖掘,首先得有数据。sklearn 库的datasets 模块中自带了一些数据集,可以方便我们使用。
sklearn 自带数据集:
- 鸢尾花数据集:load_iris()
- 乳腺癌数据集:load_breast_cancer()
- 手写数字数据集:load_digits()
- 糖尿病数据集:load_diabetes()
- 波士顿房价数据集:load_boston()
- 体能训练数据集:load_linnerud()
- 葡萄酒产地数据集:load_wine()
冒号后边是每个数据集对应的函数,可以使用相应的函数来导入数据。
比如我们用如下代码导入鸢尾花数据集:
from sklearn.datasets import load_iris
iris = load_iris()
使用dir(iris) 查看iris 中包含哪些属性:
>>> dir(iris)
['DESCR', 'data', 'feature_names', 'filename', 'frame', 'target', 'target_names']
2,sklearn 中的决策树
sklearn 库的tree 模块实现了两种决策树:
sklearn.tree.DecisionTreeClassifier类:分类树的实现。sklearn.tree.DecisionTreeRegressor类:回归树的实现。
分类树用于预测离散型数值,回归树用于预测连续性数值。
sklearn 中的决策树没有集成剪枝步骤。如果要对决策树进行缩减,可以在初始化决策树对象时,对参数进行设置,比如:
- max_depth 表示树的最大深度;
- max_leaf_nodes 表示最大的叶子节点数。
DecisionTreeClassifier 类的构造函数
def __init__(self, *,
criterion="gini",
splitter="best",
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.,
max_features=None,
random_state=None,
max_leaf_nodes=None,
min_impurity_decrease=0.,
min_impurity_split=None,
class_weight=None,
ccp_alpha=0.0):
DecisionTreeClassifier 类的构造函数中的criterion 参数有2 个取值:
entropy:表示使用 ID3 算法(信息增益)构造决策树。gini:表示使用CART 算法(基尼系数)构造决策树,为默认值。
其它参数可使用默认值。
sklearn 库中的决策分类树只实现了ID3 算法和CART 算法。
DecisionTreeRegressor 类的构造函数
def __init__(self, *,
criterion="mse",
splitter="best",
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.,
max_features=None,
random_state=None,
max_leaf_nodes=None,
min_impurity_decrease=0.,
min_impurity_split=None,
ccp_alpha=0.0):
DecisionTreeRegressor 类的构造函数中的criterion 参数有4 个取值:
mse:表示均方误差算法,为默认值。friedman_mse:表示费尔德曼均方误差算法。mae:表示平均误差算法。poisson:表示泊松偏差算法。
其它参数可使用默认值。
3,构造分类树
我们使用 sklearn.datasets 模块中自带的鸢尾花数据集 构造一颗决策树。
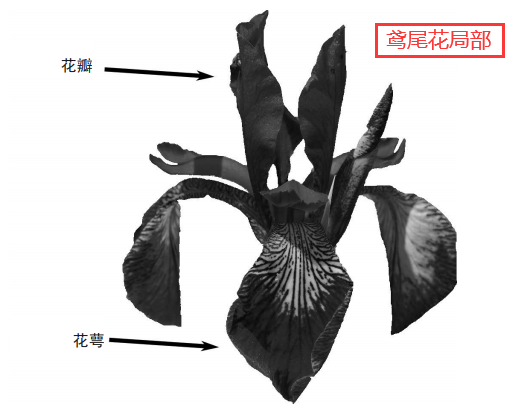
3.1,鸢尾花数据集
鸢尾花数据集目的是通过花瓣的长度和宽度,及花萼的长度和宽度,预测出花的品种。
这个数据集包含150条数据,将鸢尾花分成了三类(每类是50条数据),分别是:
setosa,用数字0表示。versicolor,用数字1表示。virginica,用数字2表示。
我们抽出3 条数据如下:
5.1,3.5,1.4,0.2,0
6.9,3.1,4.9,1.5,1
5.9,3.0,5.1,1.8,2
数据的含义:
- 每条数据包含5 列,列与列之间用逗号隔开。
- 从第1 列到第5 列,每列代表的含义是:花萼长度,花萼宽度,花瓣长度,花瓣宽度,花的品种。
- 在机器学习中,前4列称为
特征值,最后1列称为目标值。我们的目的就是用特征值预测出目标值。
将上面3 条数据,用表格表示就是:
| 花萼长度 | 花萼宽度 | 花瓣长度 | 花瓣宽度 | 花的品种 |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | 0 |
| 6.9 | 3.1 | 4.9 | 1.5 | 1 |
| 5.9 | 3.0 | 5.1 | 1.8 | 2 |
3.2,构造分类树
首先导入必要的类和函数:
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
其中:
DecisionTreeClassifier类用于构造决策树。load_iris()函数用于导入数据。train_test_split()函数用于将数据集拆分成训练集与测试集。accuracy_score()函数用于为模型的准确度进行评分。
导入数据集:
iris = load_iris() # 准备数据集
features = iris.data # 获取特征集
labels = iris.target # 获取目标集
将数据分成训练集和测试集,训练集用于训练模型,测试集用于测试模型的准确度。
train_features, test_features, train_labels, test_labels =
train_test_split(features, labels, test_size=0.33, random_state=0)
我们向train_test_split() 函数中传递了4 个参数,分别是:
- features:特征集。
- labels:目标集。
- test_size=0.33:测试集数据所占百分比,剩下的数据分给训练集。
- random_state=0:随机数种子。
该函数返回4 个值,分别是:
- train_features:训练特征集。
- test_features:测试特征集。
- train_labels:训练目标集。
- test_labels:测试目标集。
接下来构造决策树:
# 用CART 算法构建分类树(你也可以使用ID3 算法构建)
clf = DecisionTreeClassifier(criterion='gini')
# 用训练集拟合构造CART分类树
clf = clf.fit(train_features, train_labels)
上面两句代码已经在注释中说明,最终我们得到了决策树clf(classifier 的缩写)。
用clf 预测测试集数据,test_predict 为预测结果:
test_predict = clf.predict(test_features)
计算预测结果的准确率:
score = accuracy_score(test_labels, test_predict)
score2 = clf.score(test_features, test_labels)
print(score, score2)
最终得出,sorce 和 score2都为 0.96,意思就是我们训练出的模型的准确率为96%。
函数accuracy_score() 和 clf.score() 都可以计算模型的准确率,但注意这两个函数的参数不同。
4,打印决策树
为了清楚的知道,我们构造出的这个决策树cfl 到底是什么样子,可使用 graphviz 模块将决策树画出来。
代码如下:
from sklearn.tree import export_graphviz
import graphviz
# clf 为决策树对象
dot_data = export_graphviz(clf)
graph = graphviz.Source(dot_data)
# 生成 Source.gv.pdf 文件,并打开
graph.view()
为了画出决策树,除了需要安装相应的 Python 模块外,还需要安装Graphviz 软件。
由上面的代码,我们得到的决策树图如下:

我们以根节点为例,来解释一下每个方框里的四行数据(叶子节点是三行数据)都是什么意思。

四行数据所代表的含义:
- 第一行
X[3]<=0.75:鸢尾花数据集的特征集有4 个属性,所以对于X[n]中的n的取值范围为0<=n<=3,X[0]表示第1个属性,X[3]表示第4 个属性。X[3]<=0.75的意思就是当X[3]属性的值小于等于0.75 的时候,走左子树,否则走右子树。- X[0] 表示花萼长度。
- X[1] 表示花萼宽度。
- X[2] 表示花瓣长度。
- X[3] 表示花瓣宽度。
- 第二行
gini=0.666,表示当前的gini系数值。 - 第三行
samples=100,samples表示当前的样本数。我们知道整个数据集有150 条数据,我们选择了0.33 百分比作为测试集,那么训练集的数据就占0.67,也就是100 条数据。根节点包含所有样本集,所以根节点的samples值为100。 - 第四行
value:value表示属于该节点的每个类别的样本个数,value是一个数组,数组中的元素之和为samples值。我们知道该数据集的目标集中共有3 个类别,分别为:setosa,versicolor和virginica。所以:value[0]表示该节点中setosa种类的数据量,即34。value[1]表示该节点中versicolor种类的数据量,即31。value[2]表示该节点中virginica种类的数据量,即35。
4.1,打印特征重要性
我们构造出来的决策树对象clf 中,有一个feature_importances_ 属性,如下:
>>> clf.feature_importances_
array([0, 0.02252929, 0.88894654, 0.08852417])
clf.feature_importances_ 是一个数组类型,里边的元素分别代表对应特征的重要性,所有元素之和为1。元素的值越大,则对应的特征越重要。
所以,从这个数组,我们可以知道,四个特征的重要性排序为:
- 花瓣长度 > 花瓣宽度 > 花萼宽度 > 花萼长度
我们可以使用下面这个函数,将该数组画成柱状图:
import matplotlib.pyplot as plt
import numpy as np
# mode 是我们训练出的模型,即决策树对象
# data 是原始数据集
def plot_feature_importances(model, data):
n_features = data.data.shape[1]
plt.barh(range(n_features), model.feature_importances_, align='center')
plt.yticks(np.arange(n_features), data.feature_names)
plt.xlabel("Feature importance")
plt.ylabel("Feature")
plt.show()
plot_feature_importances(clf, iris)
下图是用plot_feature_importances() 函数生成的柱状图(红字是我添加的),从图中可以清楚的看出每个特种的重要性。
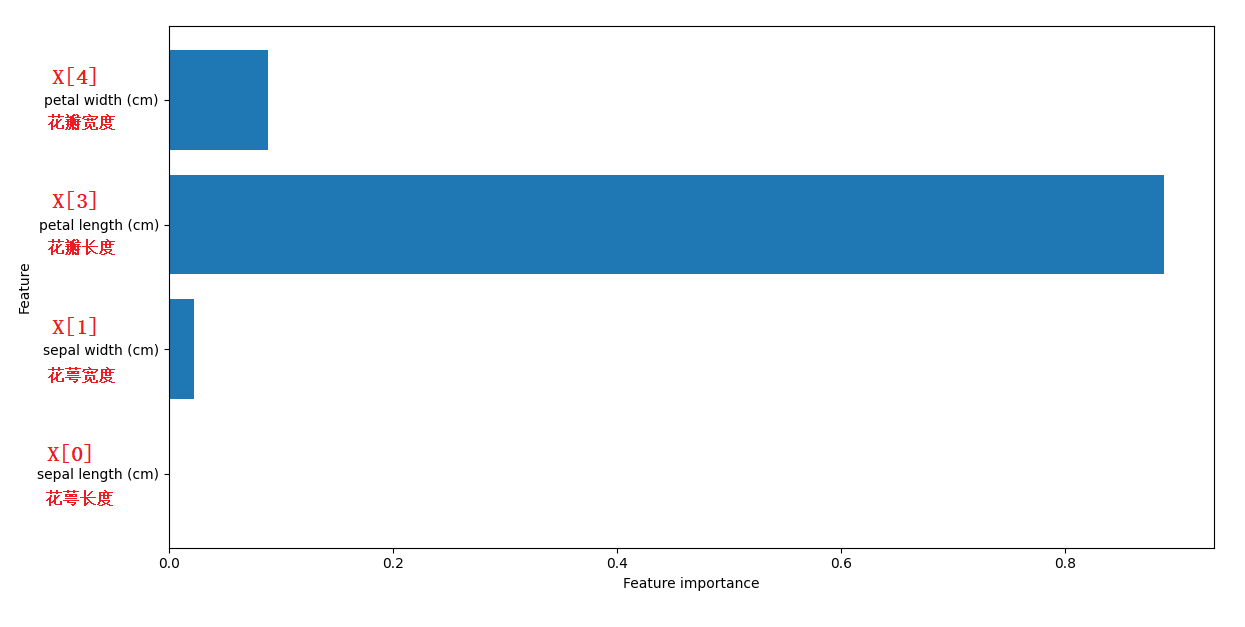 从该图中也可以看出,为什么决策树的根节点的特征是
从该图中也可以看出,为什么决策树的根节点的特征是X[3]。
5,构造回归树
我们已经用鸢尾花数据集构造了一棵分类树,下面我们用波士顿房价数据集构造一颗回归树。
来看几条数据:

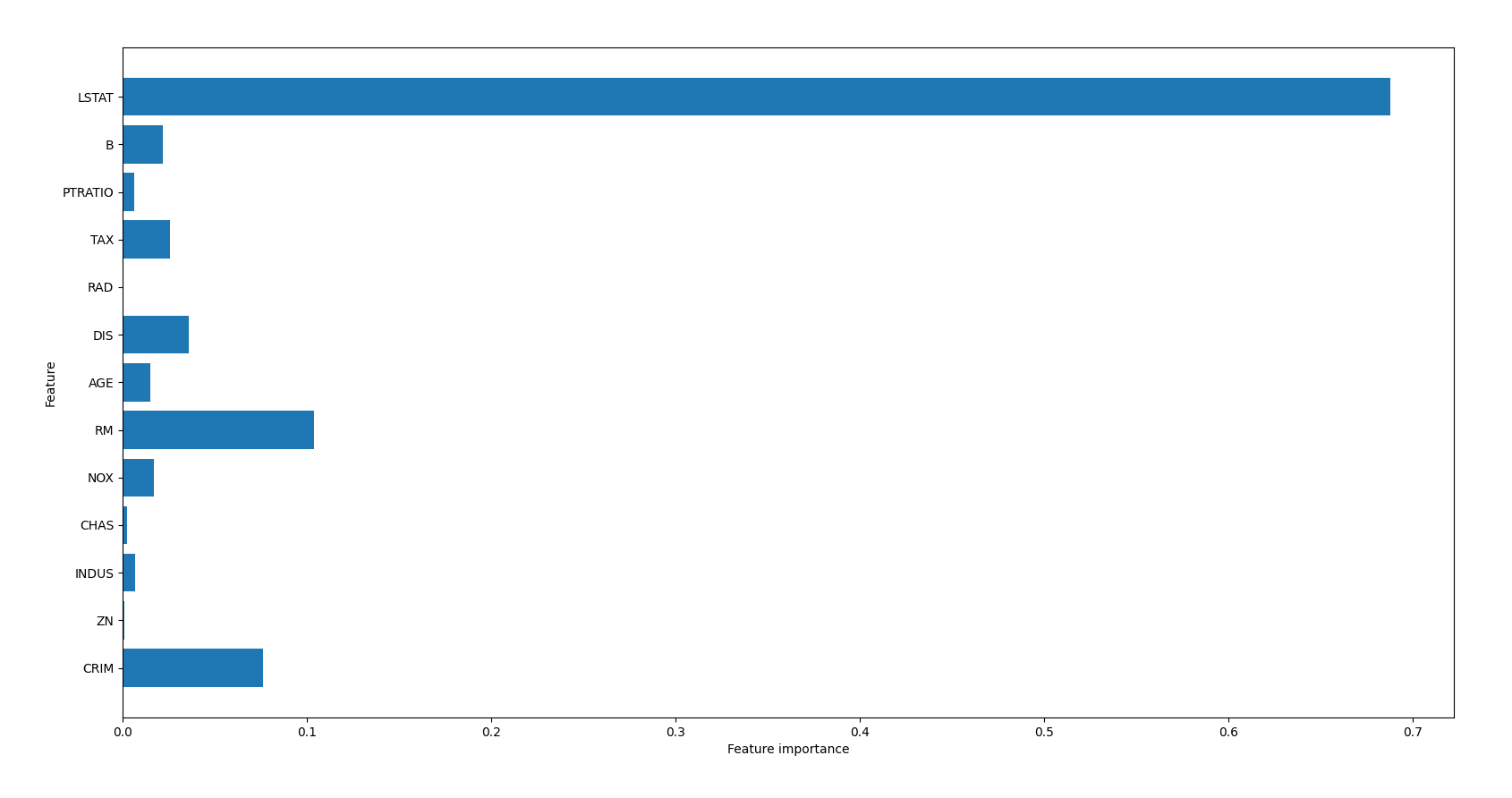
首先,我们认为房价是有很多因素影响的,在这个数据集中,影响房价的因素有13 个:
- “CRIM”,人均犯罪率。
- “ZN”,住宅用地占比。
- “INDUS”,非商业用地占比。
- “CHAS”,查尔斯河虚拟变量,用于回归分析。
- “NOX”,环保指数。
- “RM”,每个住宅的房间数。
- “AGE”,1940 年之前建成的房屋比例。
- “DIS”,距离五个波士顿就业中心的加权距离。
- “RAD”,距离高速公路的便利指数。
- “TAX”,每一万美元的不动产税率。
- “PTRATIO”,城镇中教师学生比例。
- “B”,城镇中黑人比例。
- “LSTAT”,地区有多少百分比的房东属于是低收入阶层。
数据中的最后一列的数据是房价:
- “MEDV” ,自住房屋房价的中位数。
因为房价是一个连续值,而不是离散值,所以需要构建一棵回归树。
下面对数据进行建模,构造回归树使用DecisionTreeRegressor 类:
from sklearn.tree import DecisionTreeRegressor
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score, mean_absolute_error, mean_squared_error
# 准备数据集
boston = load_boston()
# 获取特征集和房价
features = boston.data
prices = boston.target
# 随机抽取33% 的数据作为测试集,其余为训练集
train_features, test_features, train_price, test_price =
train_test_split(features, prices, test_size=0.33)
# 创建CART回归树
dtr = DecisionTreeRegressor()
# 拟合构造CART回归树
dtr.fit(train_features, train_price)
# 预测测试集中的房价
predict_price = dtr.predict(test_features)
# 测试集的结果评价
print('回归树准确率:', dtr.score(test_features, test_price))
print('回归树r2_score:', r2_score(test_price, predict_price))
print('回归树二乘偏差均值:', mean_squared_error(test_price, predict_price))
print('回归树绝对值偏差均值:', mean_absolute_error(test_price, predict_price))
最后四行代码是计算模型的准确度,这里用了4 种方法,输出如下:
回归树准确率: 0.7030833400349499
回归树r2_score: 0.7030833400349499
回归树二乘偏差均值: 28.40730538922156
回归树绝对值偏差均值: 3.6275449101796404
需要注意,回归树与分类树预测准确度的方法不一样:
dtr.score():与分类树类似,不多说。r2_score():表示R 方误差,结果与dtr.score() 一样,取值范围是0 到1。mean_squared_error():表示均方误差,数值越小,代表准确度越高。mean_absolute_error():表示平均绝对误差,数值越小,代表准确度越高。
可以用下面代码,将构建好的决策树画成图:
from sklearn.tree import export_graphviz
import graphviz
# dtr 为决策树对象
dot_data = export_graphviz(dtr)
graph = graphviz.Source(dot_data)
# 生成 Source.gv.pdf 文件,并打开
graph.view()
这棵二叉树比较大,你可以自己生成看一下。
再来执行下面代码,看下特征重要性:
import matplotlib.pyplot as plt
import numpy as np
# mode 是我们训练出的模型,即决策树对象
# data 是原始数据集
def plot_feature_importances(model, data):
n_features = data.data.shape[1]
plt.barh(range(n_features), model.feature_importances_, align='center')
plt.yticks(np.arange(n_features), data.feature_names)
plt.xlabel("Feature importance")
plt.ylabel("Feature")
plt.show()
plot_feature_importances(dtr, boston)
从生成的柱状图,可以看到LSTAT 对房价的影响最大:
6,关于数据准备
本文中用到的数据是sklearn 中自带的数据,数据完整性比较好,所以我们没有对数据进行预处理。实际项目中,可能数据比较杂乱,所以在构建模型之前,先要对数据进行预处理。
-
要对数据有个清楚的认识,每个特征的含义。如果有特别明显的特征对我们要预测的目标集没有影响,则要将这些数据从训练集中删除。
-
如果某些特征有数据缺失,需要对数据进行补全,可以使用著名的 Pandas 模块对数据进行预处理。如果某特征的数据缺失严重,则应该将其从训练集中删除。对于需要补全的值:
- 如果缺失的值是离散型数据,可以用出现次数最多的值去补全缺失值。
- 如果缺失的值是连续型数据,可以用该特征的平均值去补全缺失值。
-
如果某些特征的值是字符串类型数据,则需要将这些数据转为数值型数据。
- 可以使用
sklearn.feature_extraction模块中的DictVectorizer类来处理(转换成数字0/1)。
- 可以使用
-
在测试模型的准确率时,如果测试集中只有特征值没有目标值,就不好对测试结果进行验证。此时有两种方法来测试模型准确率:
- 在构造模型之前,用
train_test_split() 函数将原始数据集(含有目标集)拆分成训练集和测试集。 - 使用
sklearn.model_selection模块中的cross_val_score函数进行K 折交叉验证来计算准确率。
- 在构造模型之前,用
K 折交叉验证原理很简单:
- 将数据集平均分成K 个等份,
K一般取10。- 使用K 份中的1 份作为测试数据,其余为训练数据,然后进行准确率计算。
- 进行多次以上步骤,求平均值。
7,总结
本篇文章介绍了如何用决策树来处理实际问题。主要介绍了以下知识点:
sklearn是基于Python的一个机器学习库。sklearn.datasets模块中有一些自带数据集供我们使用。- 用
sklearn.tree中的两个类来构建分类树和回归树:DecisionTreeClassifier类:构造决策分类树,用于预测离散值。DecisionTreeRegressor类:构造决策回归树,用于预测连续值。
- 分别介绍了两个类的构造函数中的
criterion参数的含义。 - 介绍了几个重要函数的用途:
train_test_split() 函数用于拆分数据集。o.fit() 用于拟合决策树。(o表示决策树对象)o.predict() 用于预测数据。o.score() 用于给模型的准确度评分。accuracy_score() 函数用于给分类树模型评分。r2_score() 函数用于给回归树模型评分。mean_squared_error() 函数用于给回归树模型评分。mean_absolute_error() 函数用于给回归树模型评分。
- 介绍了如何给决策树画图。
- 介绍了如何给特征重要性画图。
(本节完。)
推荐阅读:
欢迎关注作者公众号,获取更多技术干货。

文章作者 @码农加油站
上次更改 2020-11-15