JVM性能调优实战笔记2
目录
公号:码农充电站pro
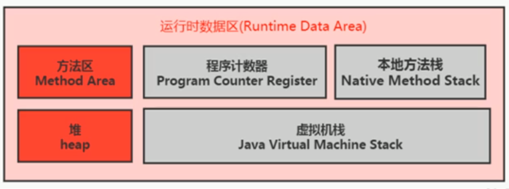
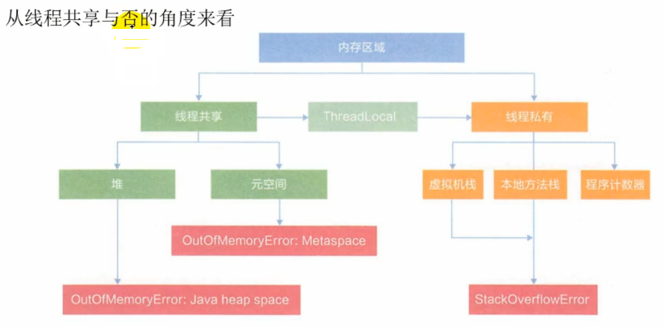
6,线程私有空间-TLAB



7,逃逸分析

对于没有发生逃逸的对象,可将其内存分配在栈上,从而减少堆的使用。
代码分析:
案例 1:


结论:开发中能使用局部变量的,就不要在方法外定义。
9,方法区
方法区(又叫非堆)是一块独立于堆的内存空间。
- 其大小可设置
- 方法区的大小决定了系统可以保存多少个类,如果系统定义了太多的类,导致方法区溢出,JVM 会抛出内存溢出错误:
- OutOfMemoryError:PermGen space(Jdk7 及之前)
- OutOfMemoryError:Metaspace (Jdk8 及之后)
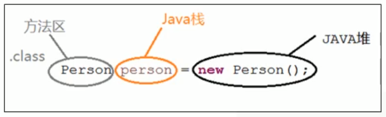
结合代码看:
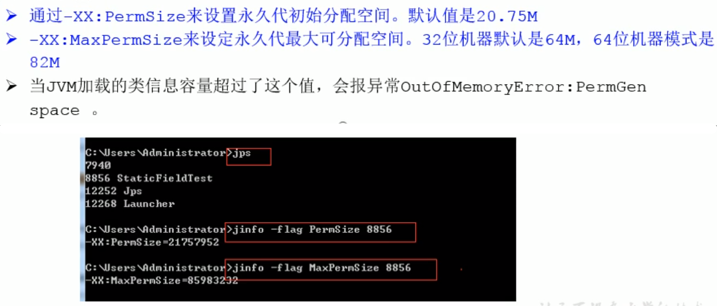
1,设置方法区的大小
方法区的大小不必是固定的,jvm 可以根据应用的需要动态调整。
JDK7 及以前:
JDK8 及以后:

2,方法区的内部结构
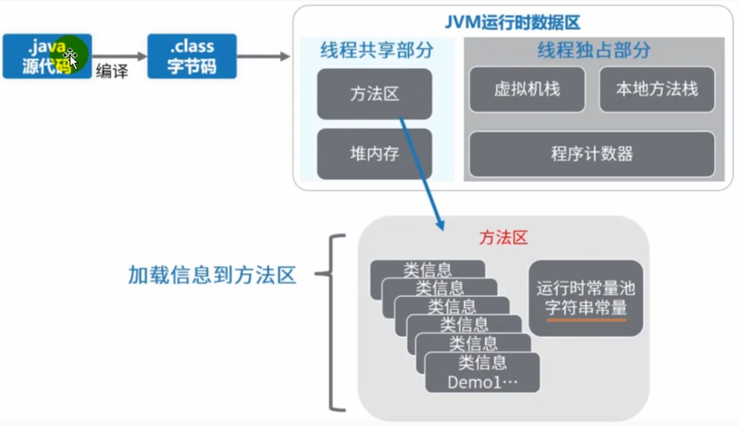
方法区主要存储的内容有:
- 类型信息(class,interface,enum,annotation)
- 域信息:域名称、域类型、域修饰符、域的声明顺序
- 方法信息:方法名称、返回类型、参数信息、方法修饰符、方法声明顺序等
- 常量
- 静态变量
- 即时编译器编译后的代码缓存
- 等
3,运行时常量池
常量池中的数据类型包括:
- 数字值
- 字符串
- 类引用
- 字段引用
- 方法引用
关于运行时常量池:
- 运行时常量池是方法区的一部分
- 常量池表是 Class 文件的一部分,用于存放编译期生成的各种字面量与符号引用,这部分内容将在类加载后存放到方法区的运行时常量池
- JVM 为每个已加载的类型都维护一个常量池,池中的数据项如数组项一样,通过索引访问
- 运行时常量池类似传统编程语言中的符号表,但是它所包含的数据比符号表更加丰富
10,String 的基本特性
- String 是 final 的,不可被继承
- String 内部:
- jdk8 及之前内部是 char[],字符数组
- jdk9 及之后内部是 byte[],字节数组,更加节省空间
- String 的两种声明方式:
String a = "123";存储在字符串常量池中- 常量池是堆的一部分
- 常量池中不会有重复的字符串
- 常量池中的字符串是不可变的
- 常量池是一个固定大小的 Hashtable
- jdk6 中池的默认大小是 1009
- jdk7 中池的默认大小是 60013,最小值是 1009
- 可通过
-XX:StringTableSize设置池的大小
String s = new String("xxx"); s.intern();方法:- 如果常量池中有 s 对应的字符串,则将 s 指向池中的串
- 如果常量池中没有 s 对应的字符串,则先在池中生成串,再将 s 指向池中的串
String b = new String("456");存储在堆中
String s1 = "Runoob"; // String 直接创建
String s2 = "Runoob"; // String 直接创建
String s3 = s1; // 相同引用
String s4 = new String("Runoob"); // String 对象创建
String s5 = new String("Runoob"); // String 对象创建
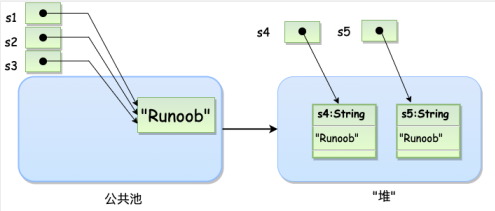
1,常量池
常量池不只有字符串常量池,也有其它基本数据类型的常量池。
Java 语言中有 8 种基本数据类型,和比较特殊的类型 String。为了使这些内容在运行时更快,更节省内存,都提供了常量池的概念。
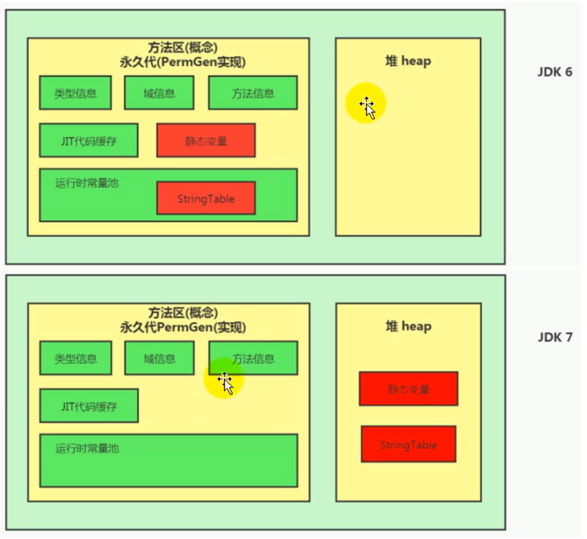
运行时常量池的空间比较小,所以 StringTable 移到了堆中。
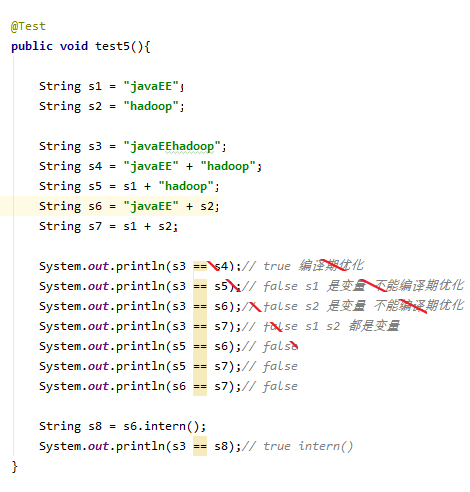
2,字符串的拼接
- 常量与常量的拼接,结果在常量池,原理是编译期优化
- 只要其中有一个是变量,结果就在堆中。变量拼接的原理是 StringBuilder
11,垃圾回收
什么是垃圾?
- 没有任何指针指向的对象
Java 垃圾回收的区域:
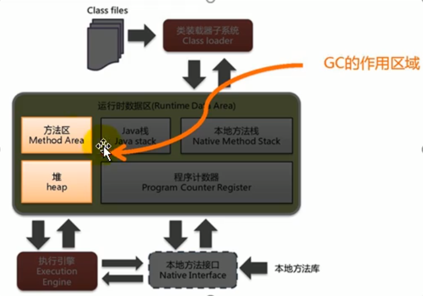
Java 堆(Heap)是垃圾回收的重点区域,从回收频率上讲:
- 年轻代,频繁收集
- 老年代,较少收集
- 永久代 / 元空间,基本不收集
12,垃圾回收算法
垃圾回收有两个阶段:
- 标记阶段(确认哪些是垃圾),有两种算法:
- 引用计数算法:对每个对象保存一个整型的引用计数属性,用于记录对象被引用的次数(Python 使用)
- 优点:实现简单,垃圾对象便于辨识;判定效率高,回收没有延迟性
- 缺点:无法处理循环引用的情况(致命缺点,导致该算法无法使用)
- 可达性分析算法:也叫追踪性垃圾收集(Java,C# 使用)
- 思路:以根对象(GC Roots)为起始点,从上到下搜索每个对象是否可达
- 内存中的存活对象都会被根对象直接或间接连接着,搜索所走过的路径称为引用链,如果目标对象没有与任何引用链相连,则是不可达的
- 优点:实现简单,执行高效,能处理循环引用的情况
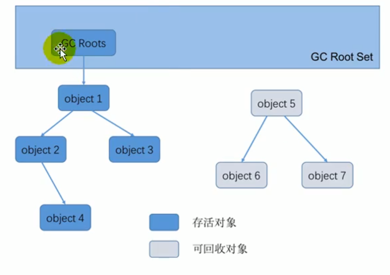
- Java 语音中可以作为 GC Roots 的对象包括以下几类:
- 虚拟机栈中引用的对象
- 本地方法栈内 JNI 引用的对象
- 方法区中静态属性引用的对象
- 方法区中常量引用的对象
- 所有被同步锁 synchronized 持有的对象
- Java 虚拟机内部的引用
- 等
- 引用计数算法:对每个对象保存一个整型的引用计数属性,用于记录对象被引用的次数(Python 使用)
- 清除阶段(清理垃圾),有三种算法:
- 标记-清除算法:该算法在 1960 年提出并应用于 Lisp 语言
- 标记:从引用根节点开始遍历,标记所有被引用的对象(可达对象)
- 清除:对所有不可达的对象进行回收
- 缺点:效率不高,需要遍历两次,标记一次,清除一次
- 复制算法:将内存空间分为两块,每次只使用其中一块;在垃圾回收时,将正在使用的内存中的存活对象复制到未被使用的内存块中,然后清除正在使用的内存块中的所有对象,然后交换两个内存的角色
- 优点:没有标记和清除过程,实现简单,运行高效,不会出现内存碎片
- 缺点:需要两倍的内存空间
- 比较适用于垃圾比较多的情况(新生代中的幸存者区使用的就是该算法)
- 标记-压缩(整理)算法:其最终效果等同于标记-清除算法执行后,再进行一次内存碎片整理
- 比标记-清除算法多了一个整理内存碎片的阶段
- 比复制算法多了一个标记的阶段
- 分代收集算法:不同的对象的生命周期是不一样的,不同生命周期的对象可以使用不同的收集方式,以便可以提高效率
- 比如 Java 堆分为新生代和老年代
- 分代的思想被现在的虚拟机广泛使用,几乎所有的垃圾收集器都区分新生代和老年代
- 增量收集算法:如果一次性将所有的垃圾进行处理,需要造成系统长时间停顿,那就让垃圾收集线程和应用程序线程交替执行。每次垃圾收集线程只收集一小片区域的内存空间,接着切换到应用程序线程。依次反复,直到垃圾收集完成
- 其基础仍是传统的标记-清除和复制算法
- 缺点:线程切换和上下文转换的消耗,会使得垃圾回收的总体成本上升,造成系统吞吐量下降
- 分区算法
- 分代算法按照对象的生命周期长短划分为两部分,分区算法将整个堆空间划分为不同的小区间
- 每个小区间都独立使用,独立回收
- 标记-清除算法:该算法在 1960 年提出并应用于 Lisp 语言
使用 MAT 查看 GC Roots:
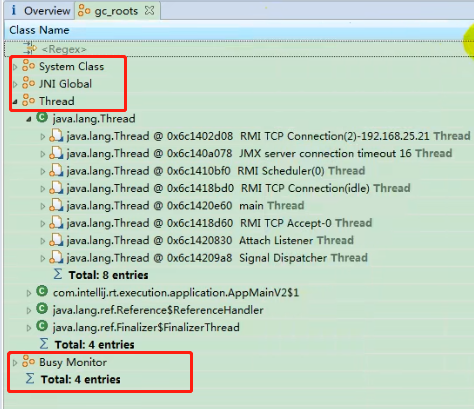
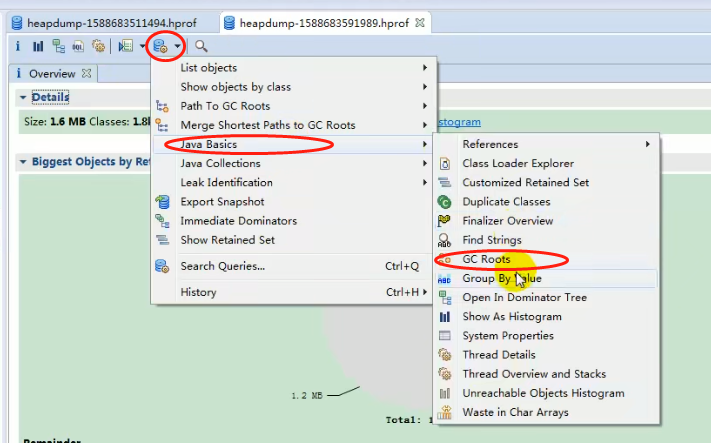 GC Roots 如下:
GC Roots 如下:
三种清除阶段算法的对比:
| 标记清除算法 | 标记压缩算法 | 复制算法 | |
|---|---|---|---|
| 速度 | 中等 | 最慢 | 最快 |
| 空间开销 | 少 | 少 | 2倍空间 |
| 移动对象 | 否 | 否 | 是 |
没有最好的算法,只有最合适的算法。 实际的 GC 要复杂的多,大部分都是复合算法。
13,Java 中的几种引用
我们希望能描述这样一类对象:
- 当内存空间足够时,则能留在内存中
- 当内存空间短缺是,则可回收它们
在 JDK1.2 后,Java 将引用分为四种:

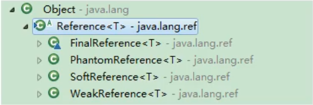
1,强引用-永远不回收


2,软引用-内存不够即回收

发生 OOM 的时候会回收软引用
3,弱引用-GC 即回收


4,虚引用-对象回收跟踪


14,垃圾回收器
1,垃圾回收器的分类
7 款经典的垃圾回收器:
-
串行回收器:只使用一个CPU,且在进行垃圾回收时,必须暂停其它所有工作线程(Stop-The-World)
- Serial:最基本、最悠久的GC
- JDK1.3 之前新生代唯一选择;HotSpot 中 Client 模式下默认新生代 GC
- 采用复制算法,串行回收
-XX:+UseSerialGC参数可指定串行收集器
- Serial Old
- HotSpot 中 Client 模式下默认老年代 GC
- 采用标记-压缩算法,串行回收
- 在 Server 模式下有两种用途:
- 与新生代 Parallel Scavenge 配合使用
- 作为老年代 CMS 收集器的后备方案
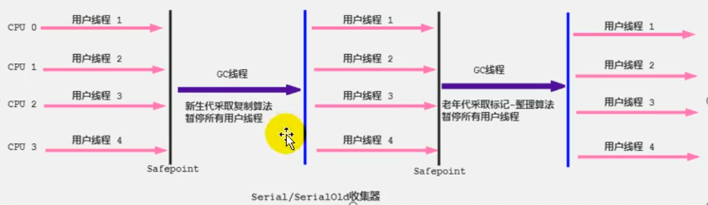
- Serial:最基本、最悠久的GC
-
并行回收器:
- ParNew:Serial 的多线程版本,只处理新生代
- 采用复制算法,串行回收
- 参数
-XX:+UseParNewGC年轻代使用并行收集器,不影响老年代-XX:ParallelGCThreads设置并行线程数,默认与CPU 数相同
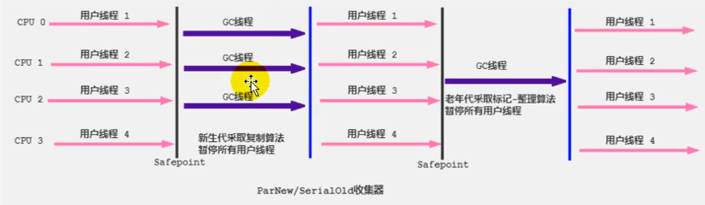
- Parallel Scavenge(JDK8 默认):主打吞吐量,只处理新生代
- 采用复制算法,并行回收
- 自适应调节策略(自动调整) 也是与 ParNew 的一个重要区别
- 参数
-XX:+UseAdaptiveSizePolicy默认开启 - 在这种模式下,年轻代的大小,Eden 和 Survivor 的比例、晋升老年代的年龄等参数会被自动调整
- 参数
- 相关参数:
-XX:+UseParallelGC:与下面的一个参数互相激活-XX:+UseParallelOldGC-XX:+ParallelGCThreads:设置并行线程数;当 CPU 数小于 8 时,默认为 CPU 数,当CPU 数大于 8 时,默认为3+[5*CPU_Count]/8
- Parallel Old(JDK8 默认)
- 采用标记-压缩算法,并行回收
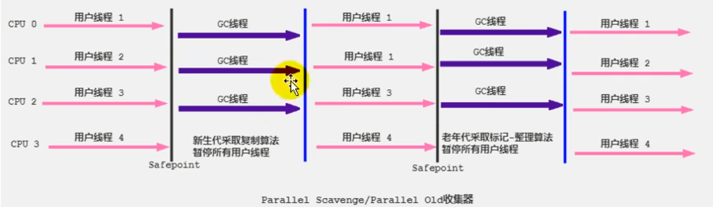
- ParNew:Serial 的多线程版本,只处理新生代
-
并发回收器:
- CMS(Concurrent-Mark-Sweep):老年代GC,主打低延迟
- 在 JDK1.5 时,HotSpot 推出的,强交互应用中,认为是划时代意义的 GC
- 是 HotSpot 中第一款并发 GC,第一次实现了让 GC线程与用户线程同时工作
- 采用标记-清除算法
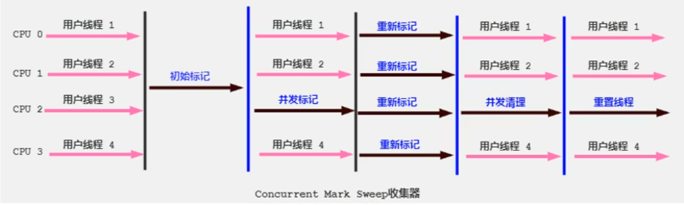
- 参数
-XX:+UseConcMarkSweepGC(老年代)指定 CMS GC,该参数会将-XX:+UseParNewGC(新生代)打开 - 已被 JDK9 废弃,已被 JDK14 删除
- G1(JDK9 默认):区域分代化 GC,其目标是在延迟可控的情况下获得尽可能高的吞吐量
- G1 把堆内存分割为很多不同的区域,避免在整个堆中进行全区域的垃圾收集,优先回收垃圾最大量的区域
- 参数
-XX:+UseG1GC -XX:G1HeapRegionSize设置每个 Region 的大小,值是 2 的幂,范围是 1MB ~ 32MB 之间,默认是堆内存的 1 /2000-XX:MaxGCPauseMillis设置期望达到的最大 GC 停顿时间指标,默认 200ms
- ZGC:未来 GC,目前处于实验阶段
- CMS(Concurrent-Mark-Sweep):老年代GC,主打低延迟

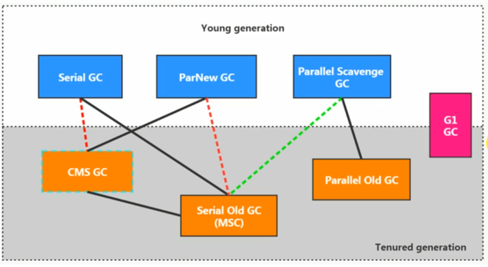

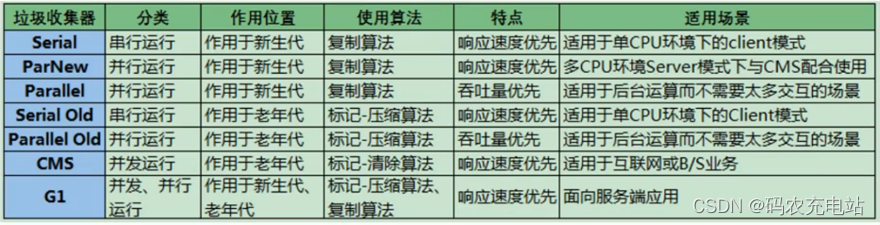
7 款垃圾回收器总结:
2,查看正在使用的 GC
两种方式:
-XX:+PrintCommandLineFlagsjinfo -flag 相关垃圾回收器参数 进程ID
JDK8:
UseParallelGC、UseParallelOldGCJDK9:UseG1GC
15,Class 文件结构
任何一个 Class 文件都对应着唯一一个类或接口的定义信息。Class 文件的结构并不是一成不变的,随着 Java 虚拟机的不断发展,总是不可避免的会对 Class 文件结构做出调整,但其基本结构和框架是稳定的。

Class 文件的总体结构如下:
- 魔数:cafebabe
- Class 文件版本
- 常量池
- 访问标志
- 类索引、父类索引、接口索引集合
- 字段表集合
- 方法表集合
- 属性表集合
16,类的加载
Java 中的数据类型分为基本数据类型和引用数据类型,基本数据类型由虚拟机预先定义,引用数据类型则需要类的加载。
按照 Java 虚拟机规范,从 class 文件到加载到内存中的类,再到类卸载出内存为止,它的生命周期包括 7 个阶段:
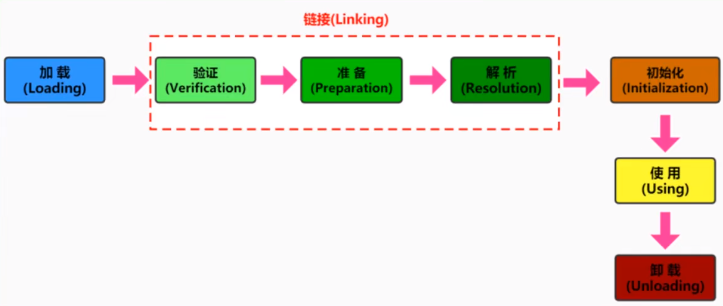
初始化之后的类会放在方法区
17,类的加载器
ClassLoader 是 Java 的核心最贱,所有的 Class 都是由 ClassLoader 进行加载的,ClassLoader 通过各种方式将 Class 信息的二进制数据流读入 JVM 内部。
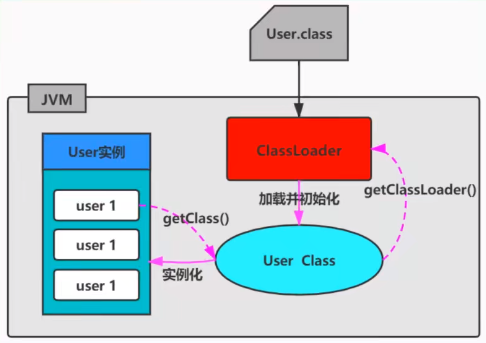
类的唯一性:
- 任意一个类,都需要由加载它的类加载器和这个类本身一起确认其在 Java 虚拟机中的唯一性。
- 每一个类加载器,拥有一个独立的类名称空间,比较两个类是否相等,只有在这两个类是由同一个类加载器加载的前提下才有意义。
- 否则,即使这两个类源自同一个 Class 文件,被同一个虚拟机加载,只要加载它的类加载器不同,那这两个类就必定是不同的。
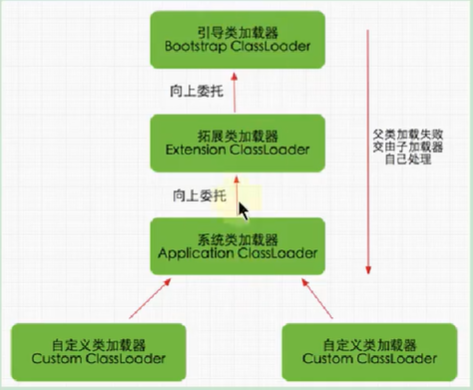
18,双亲委派机制
类加载器把类加载到 Java 虚拟机中,从 JDK1.2 开始,类的加载过程采用双亲委派机制,更好地保证 Java 平台的安全。
- 确保一个类的全局唯一性,避免类的重复加载
- Java 类随着它的类加载器一起具备了一种带有优先级的层次关系,通过这种层级关系可以避免类的重复加载,当父亲已经加载了该类时,就不需子类加载器再加载一次
- 保护程序安全,防止核心 API 被篡改
定义:当一个类加载器在接到加载类的请求时,它首先不会自己尝试去加载这个类,而是把这个请求任务委托给父类加载器去完成,如果父类加载器可以完成类加载任务,就返回成功。只有父类加载器无法完成此加载任务时,才自己去加载。
该机制规定了类加载的顺序:
- 引导类加载器先加载,若加载不到,由扩展类加载器加载
- 若还加载不到,才会由系统类加载器或自定义类加载器进行加载
文章作者 @码农加油站
上次更改 2022-03-18