ElasticSearch 搜索引擎概念简介
目录
公号:码农充电站pro
1,倒排索引
倒排索引是一种数据结构,经常用在搜索引擎的实现中,用于快速找到某个单词所在的文档。
倒排索引会记录一个单词词典(Term Dictionary)和一个倒排列表:
- 单词词典:包含了所有文档包含的所有 Term。
- 倒排列表:由一系列的倒排索引项组成,每个倒排索引项包含 4 项内容,分别是:
- 文档 ID
- 词频 TF:Term 在文档中出现的次数,用于相关性评分。
- 位置 Position:Term 在文档中出现的位置,用于语句搜索。
- 偏移 Offset:记录单词的开始结束位置,用于实现高亮显示。
假设我们有 3 篇文档:
| 文档 ID | 文档内容 |
|---|---|
| 1 | hello world |
| 2 | hello Java |
| 3 | hello elasticsearch |
上面表格记录的是一种正向关系,叫做正排索引。
倒排索引记录的是一种反向关系,如下:
| Term | 文档 ID | 词频 TF | Position | Offset |
|---|---|---|---|---|
| hello | 1 | 1 | 0 | <0, 5> |
| hello | 2 | 1 | 0 | <0, 5> |
| hello | 3 | 1 | 0 | <0, 5> |
| world | 1 | 1 | 1 | <6, 5> |
| Java | 2 | 1 | 1 | <6, 4> |
| elasticsearch | 3 | 1 | 1 | <6, 19> |
ES 默认会对所有文档的所有字段建立倒排索引;也可以通过设置不对某些字段建立倒排索引,优点是节省空间,缺点是这些字段的内容无法被搜索。
2,搜索相关性
搜索相关性用于描述文档与搜索字符串的匹配程度(ES 会计算出一个评分),目的是为文档进行排序,从而将最符合用户需求的文档排在前面。
搜索相关性算法有 TF-IDF 算法和 BM25 算法。
文章 《朴素贝叶斯分类-实战篇》中介绍到了 TF-IDF 算法,可作为参考。
BM25 与 TF-IDF 的比较:
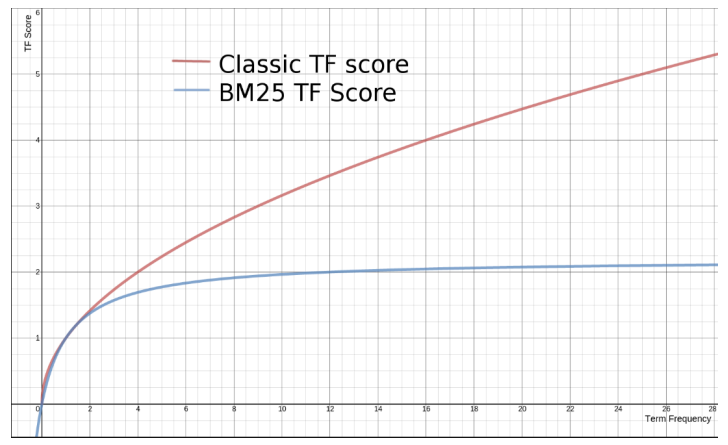
当 TF 无限增加的时候,BM25 算分会趋向于一个数值,而不是(像 TF-IDF 一样)无限增长。
在 ES 5 之前,默认使用的是 TF-IDF 算法;在 ES 5 之后,默认使用的是 BM 25 算法。
3,一个搜索过程
下图展示了一个搜索过程:
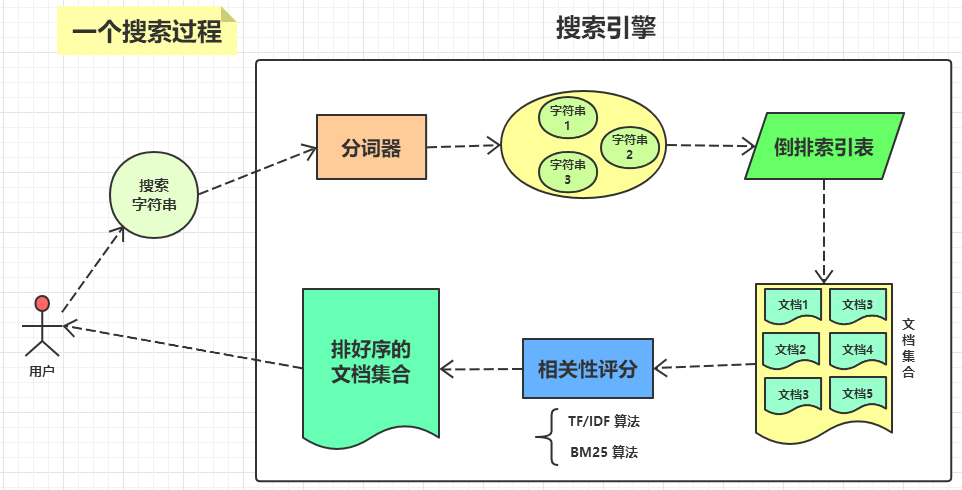
当用户向搜索引擎发送一个搜索请求的时候,搜索引擎经过了以下步骤:
- 分词器对搜索字符串进行分词处理。
- 在倒排索引表中查到匹配的文档。
- 对每个匹配的文档进行相关性评分。
- 根据相关性评分对文档进行排序。
- 将排好序的文档返回给用户。
文章作者 @码农加油站
上次更改 2021-02-05