朴素贝叶斯分类-实战篇-如何进行文本分类
目录
微信公众号:码农充电站pro
上篇介绍了朴素贝叶斯的原理,本篇来介绍如何用朴素贝叶斯解决实际问题。
朴素贝叶斯最擅长的领域是文本分析,包括:
- 文本分类
- 情感分析
- 垃圾邮件处理
要对文本进行分类,首先要做的是如何提取文本的主要信息,如何衡量哪些信息是文本中的主要信息呢?
1,对文档分词
我们知道,一篇文档是由若干词汇组成的,也就是文档的主要信息是词汇。从这个角度来看,我们就可以用一些关键词来描述文档。
这种处理文本的方法叫做词袋(bag of words)模型,该模型会忽略文本中的词语出现的顺序以及相应的语法,将文档看做是由若干单词组成的,且单词之间互相独立,没有关联。
要想提取文档中的关键词,就得先对文档进行分词。分词方法一般有两种:
- 第一种是基于字符串匹配。就是扫描字符串。如果发现字符串的子串和词相同,就算匹配成功。
- 匹配规则一般有“正向最大匹配”,“逆向最大匹配”,“长词优先”等。
- 该类算法的优点是只需基于字典匹配,算法简单;缺点是没有考虑词义,处理歧义词效果不佳。
- 第二种是基于统计和机器学习。需要人工标注词性和统计特征,对中文进行建模。
- 先要训练分词模型,然后基于模型进行计算概率,取概率最大的分词作为匹配结果。
- 常见的序列标注模型有隐马尔科夫模型和条件随机场。
停用词是一些非常普遍使用的词语,对文档分析作用不大,在文档分析之前需要将这些词去掉。比如:
- 中文停用词:“你,我,他,它,的,了” 等。
- 英文停用词:“is,a,the,this,that” 等。
- 停用词文件:停用词一般保存在文件中,需要自行读取。
另外分词阶段,还需要处理同义词,很多时候一件东西有多个不同的名字。比如“番茄”和“西红柿”,“凤梨”和“菠萝”等。
中文分词与英文分词是不同的,我们分别介绍一个著名的分词包:
2,计算单词权重
哪些关键词对一个文档才是重要的?比如可以通过单词出现的次数,次数越多就表示越重要。
更合理的方法是计算单词的TF-IDF 值。
2.1,单词的 TF-IDF 值
单词的TF-IDF 值可以描述一个单词对文档的重要性,TF-IDF 值越大,则越重要。
- TF:全称是
Term Frequency,即词频(单词出现的频率),也就是一个单词在文档中出现的次数,次数越多越重要。- 计算公式:
一个单词的词频TF = 单词出现的次数 / 文档中的总单词数
- 计算公式:
- IDF:全称是
Inverse Document Frequency,即逆向文档词频,是指一个单词在文档中的区分度。它认为一个单词出现在的文档数越少,这个单词对该文档就越重要,就越能通过这个单词把该文档和其他文档区分开。- 计算公式:
一个单词的逆向文档频率 IDF = log(文档总数 / 该单词出现的文档数 + 1) - 为了避免分母为0(有些单词可能不在文档中出现),所以在分母上加1
- 计算公式:

IDF 是一个相对权重值,公式中log 的底数可以自定义,一般可取2,10,e 为底数。
假设我们现在有一篇文章,文章中共有2000 个单词,“中国”出现100 次。假设全网共有1 亿篇文章,其中包含“中国”的有200 万篇。现在我们要求“中国”的TF-IDF值。
计算过程如下:
TF(中国) = 100 / 2000 = 0.05
IDF(中国) = log(1亿/(200万+1)) = 1.7 # 这里的log 以10 为底
TF-IDF(中国) = 0.05 * 1.7 = 0.085
通过计算文档中单词的TF-IDF 值,我们就可以提取文档中的特征属性,就是把TF-IDF 值较高的单词,作为文档的特征属性。
2.2,TfidfVectorizer 类
sklearn 库的 feature_extraction.text 模块中的 TfidfVectorizer 类,可以计算 TF-IDF 值。
TfidfVectorizer 类的原型如下:
TfidfVectorizer(*,
input='content',
encoding='utf-8',
decode_error='strict',
strip_accents=None,
lowercase=True,
preprocessor=None,
tokenizer=None,
analyzer='word',
stop_words=None,
token_pattern='(?u)\b\w\w+\b',
ngram_range=(1, 1),
max_df=1.0,
min_df=1,
max_features=None,
vocabulary=None,
binary=False,
dtype=<class 'numpy.float64'>,
norm='l2',
use_idf=True,
smooth_idf=True,
sublinear_tf=False)
常用的参数有:
input:有三种取值:- filename
- file
- content:默认值为
content。
analyzer:有三种取值,分别是:- word:默认值为
word。 - char
- char_wb
- word:默认值为
stop_words:表示停用词,有三种取值:english:会加载自带英文停用词。None:没有停用词,默认为None。List类型的对象:需要用户自行加载停用词。- 只有当参数
analyzer == 'word'时才起作用。
token_pattern:表示过滤规则,是一个正则表达式,不符合正则表达式的单词将会被过滤掉。- 注意默认的
token_pattern值为r'(?u)\b\w\w+\b',匹配两个以上的字符,如果是一个字符则匹配不上。 - 只有参数
analyzer == 'word'时,正则才起作用。
- 注意默认的
max_df:用于描述单词在文档中的最高出现率,取值范围为[0.0~1.0]。- 比如
max_df=0.6,表示一个单词在 60% 的文档中都出现过,那么认为它只携带了非常少的信息,因此就不作为分词统计。
- 比如
mid_df:单词在文档中的最低出现率,一般不用设置。
常用的方法有:
t.fit(raw_docs):用raw_docs拟合模型。t.transform(raw_docs):将raw_docs转成矩阵并返回,其中包含了每个单词在每个文档中的 TF-IDF 值。t.fit_transform(raw_docs):可理解为先fit再transform。
在上面三个方法中:
t表示TfidfVectorizer对象。raw_docs参数是一个可遍历对象,其中的每个元素表示一个文档。
fit_transform 与 transform 的用法
- 一般在拟合转换数据时,先处理训练集数据,再处理测试集数据。
- 训练集数据会用于拟合模型,而测试集数据不会用于拟合模型。所以:
fit_transform用于训练集数据。transform用于测试集数据,且transform必须在fit_transform之后。- 如果测试集数据也用
fit_transform方法,则会造成过拟合。
下图表达的很清晰明了:
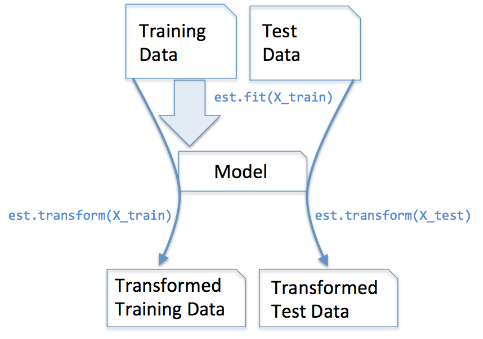 所以一般的使用步骤是:
所以一般的使用步骤是:
# x 为 DictVectorizer,DictVectorizer 等类的对象
# 用于特征提取
x = XXX()
train_features = x.fit_transform(train_datas)
test_features = x.transform(test_datas)
2.3,一个例子
比如我们有如下3 个文档(docs 的每个元素表示一个文档):
docs = [
'I am a student.',
'I live in Beijing.',
'I love China.',
]
我们用 TfidfVectorizer 类来计算TF-IDF 值:
from sklearn.feature_extraction.text import TfidfVectorizer
t = TfidfVectorizer() # 使用默认参数
用 fit_transform() 方法拟合模型,反回矩阵:
t_matrix = t.fit_transform(docs)
用 get_feature_names() 方法获取所有不重复的特征词:
>>> t.get_feature_names()
['am', 'beijing', 'china', 'in', 'live', 'love', 'student']
不知道你有没有发现,这些特征词中不包含
i和a?你能解释一下是为什么吗?
用vocabulary_ 属性获取特征词与ID 的对应关系:
>>> t.vocabulary_
{'am': 0, 'student': 6, 'live': 4, 'in': 3, 'beijing': 1, 'love': 5, 'china': 2}
用 矩阵对象的toarray() 方法输出 TF-IDF 值:
>>> t_matrix.toarray()
array([
[0.70710678, 0. , 0. , 0. , 0. , 0. , 0.70710678],
[0. , 0.57735027, 0. , 0.57735027, 0.57735027, 0. , 0. ],
[0. , 0. , 0.70710678, 0. , 0. , 0.70710678, 0. ]
])
3,sklearn 朴素贝叶斯的实现
sklearn 库中的 naive_bayes 模块实现了 5 种朴素贝叶斯算法:
naive_bayes.BernoulliNB类:伯努利朴素贝叶斯的实现。- 适用于离散型数据,适合特征变量是布尔变量,符合 0/1 分布,在文档分类中特征是单词是否出现。
- 该算法以文件为粒度,如果该单词在某文件中出现了即为 1,否则为 0。
naive_bayes.CategoricalNB类:分类朴素贝叶斯的实现。naive_bayes.GaussianNB类:高斯朴素贝叶斯的实现。- 适用于特征变量是连续型数据,符合高斯分布。比如说人的身高,物体的长度等,这种自然界物体。
naive_bayes.MultinomialNB类:多项式朴素贝叶斯的实现。- 适用于特征变量是离散型数据,符合多项分布。在文档分类中特征变量体现在一个单词出现的次数,或者是单词的 TF-IDF 值等。
naive_bayes.ComplementNB类:补充朴素贝叶斯的实现。- 是多项式朴素贝叶斯算法的一种改进。
每个类名中的NB 后缀是 Naive Bayes 的缩写,即表示朴素贝叶斯。
各个类的原型如下:
BernoulliNB(*, alpha=1.0, binarize=0.0, fit_prior=True, class_prior=None)
CategoricalNB(*, alpha=1.0, fit_prior=True, class_prior=None)
GaussianNB(*, priors=None, var_smoothing=1e-09)
MultinomialNB(*, alpha=1.0, fit_prior=True, class_prior=None)
ComplementNB(*, alpha=1.0, fit_prior=True, class_prior=None, norm=False)
构造方法中的alpha 的含义为平滑参数:
- 如果一个单词在训练样本中没有出现,这个单词的概率就会是 0。但训练集样本只是整体的抽样情况,不能因为没有观察到,就认为整个事件的概率为 0。为了解决这个问题,需要做平滑处理。
- 当 alpha=1 时,使用的是 Laplace 平滑。Laplace 平滑就是采用加 1 的方式,来统计没有出现过的单词的概率。这样当训练样本很大的时候,加 1 得到的概率变化可以忽略不计。
- 当 0<alpha<1 时,使用的是 Lidstone 平滑。对于 Lidstone 平滑来说,alpha 越小,迭代次数越多,精度越高。一般可以设置 alpha 为 0.001。
4,构建模型
我准备了一个实战案例,目录结构如下:
naive_bayes\
├── stop_word\
│ └── stopword.txt
├── test_data\
│ ├── test_economy.txt
│ ├── test_fun.txt
│ ├── test_health.txt
│ └── test_sport.txt
├── text_classification.py
└── train_data\
├── train_economy.txt
├── train_fun.txt
├── train_health.txt
└── train_sport.txt
其中:
stop_word目录中是中文停用词。train_data目录中是训练集数据。test_data目录中是测试集数据。text_classification.py:是Python 代码,包括以下步骤:- 中文分词
- 特征提取
- 模型训练
- 模型测试
这些数据是一些新闻数据,每条数据包含了新闻类型和新闻标题,类型有以下四种:
- 财经类
- 娱乐类
- 健康类
- 体育类
我们的目的是训练一个模型,该模型的输入是新闻标题,模型的输出是新闻类型,也就是想通过新闻标题来判断新闻类型。
来看下数据的样子,每类数据抽取了一条:
财经---11月20日晚间影响市场重要政策消息速递
娱乐---2020金鸡港澳台影展曝片单 修复版《蝶变》等将映
健康---全面解析耳聋耳鸣,让你不再迷茫它的危害
体育---中国军团1人已进32强!赵心童4-1晋级,丁俊晖颜丙涛将出战
可以看到,每条数据以--- 符号分隔,前边是新闻类型,后边是新闻标题。
下面来看下代码:
import os
import sys
import jieba
import warnings
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn import metrics
warnings.filterwarnings('ignore')
if sys.version.startswith('2.'):
reload(sys)
sys.setdefaultencoding('utf-8')
def load_file(file_path):
with open(file_path) as f:
lines = f.readlines()
titles = []
labels = []
for line in lines:
line = line.encode('unicode-escape').decode('unicode-escape')
line = line.strip().rstrip('\n')
_lines = line.split('---')
if len(_lines) != 2:
continue
label, title = _lines
words = jieba.cut(title)
s = ''
for w in words:
s += w + ' '
s = s.strip()
titles.append(s)
labels.append(label)
return titles, labels
def load_data(_dir):
file_list = os.listdir(_dir)
titles_list = []
labels_list = []
for file_name in file_list:
file_path = _dir + '/' + file_name
titles, labels = load_file(file_path)
titles_list += titles
labels_list += labels
return titles_list, labels_list
def load_stopwords(file_path):
with open(file_path) as f:
lines = f.readlines()
words = []
for line in lines:
line = line.encode('unicode-escape').decode('unicode-escape')
line = line.strip('\n')
words.append(line)
return words
if __name__ == '__main__':
# 加载停用词
stop_words = load_stopwords('stop_word/stopword.txt')
# 加载训练数据
train_datas, train_labels = load_data('train_data')
# 加载测试数据
test_datas, test_labels = load_data('test_data')
# 计算单词权重
tf = TfidfVectorizer(stop_words = stop_words, max_df = 0.5)
train_features = tf.fit_transform(train_datas)
test_features = tf.transform(test_datas)
# 多项式贝叶斯分类器
clf = MultinomialNB(alpha = 0.001).fit(train_features, train_labels)
# 预测数据
predicted_labels = clf.predict(test_features)
# 计算准确率
score = metrics.accuracy_score(test_labels, predicted_labels)
print score
说明:
load_stopwords函数用于加载停用词。load_data函数用于加载训练集和测试集数据。- 使用
fit_transform方法提取训练集特征。 - 使用
transform方法提取测试集特征。 - 这里使用的是多项式贝叶斯分类器—
MultinomialNB,平滑参数设置为0.001。 - 用
fit方法拟合出了模型。 - 用
predict方法对测试数据进行了预测。 - 最终用
accuracy_score方法计算了模型的准确度,为 0.959。
5,如何存储模型
实际应用中,训练一个模型需要大量的数据,也就会花费很多时间。
为了方便使用,可以将训练好的模型存储到磁盘上,在使用的时候,直接加载出来就可以使用。
可以使用 sklearn 中的 joblib 模块来存储和加载模型:
joblib.dump(obj, filepath)方法将obj存储到filepath指定的文件中。obj是要存储的对象。filepath是文件路径。
joblib.load(filepath)方法用于加载模型。filepath是文件路径。
在上边的例子用,我们需要存储两个对象,分别是:
tf:TF-IDF 值模型。cfl:朴素贝叶斯模型。
存储代码如下:
from sklearn.externals import joblib
>>> joblib.dump(clf, 'nb.pkl')
['nb.pkl']
>>> joblib.dump(tf, 'tf.pkl')
['tf.pkl']
使用模型代码如下:
import jieba
import warnings
from sklearn.externals import joblib
warnings.filterwarnings('ignore')
MODEL = None
TF = None
def load_model(model_path, tf_path):
global MODEL
global TF
MODEL = joblib.load(model_path)
TF = joblib.load(tf_path)
def nb_predict(title):
assert MODEL != None and TF != None
words = jieba.cut(title)
s = ' '.join(words)
test_features = TF.transform([s])
predicted_labels = MODEL.predict(test_features)
return predicted_labels[0]
if __name__ == '__main__':
# 加载模型
load_model('nb.pkl', 'tf.pkl')
# 测试
print nb_predict('东莞市场采购贸易联网信息平台参加部委首批联合验收')
print nb_predict('留在中超了!踢进生死战决胜一球,武汉卓尔保级成功')
print nb_predict('陈思诚全新系列电影《外太空的莫扎特》首曝海报 黄渤、荣梓杉演父子')
print nb_predict('红薯的好处 常吃这种食物能够帮你减肥')
其中:
load_model()函数用于加载模型。nb_predict()函数用于对新闻标题进行预测,返回标题的类型。
6,总结
本篇文章介绍了如何利用朴素贝叶斯处理文本分类问题:
- 首先需要对文本进行分词,常用的分词包有:
- 使用
TfidfVectorizer计算单词权重。- 使用
fit_transform方法提取训练集特征。 - 使用
transform方法提取测试集特征。
- 使用
- 使用
MultinomialNB类训练模型,这里给出了一个实战项目,供大家参考。 - 使用 joblib 存储模型,方便模型的使用。
(本节完。)
推荐阅读:
欢迎关注作者公众号,获取更多技术干货。

文章作者 @码农加油站
上次更改 2020-11-23